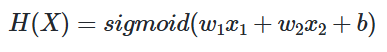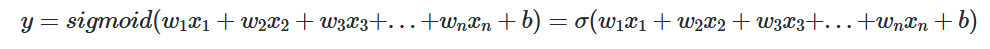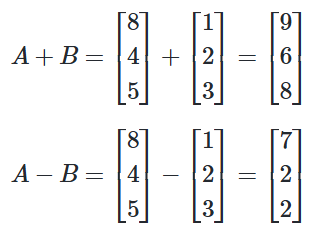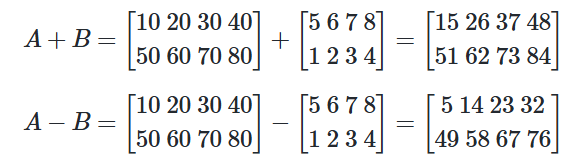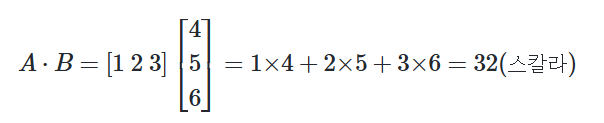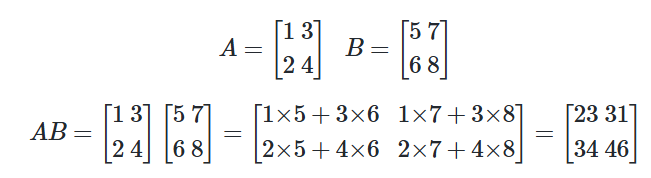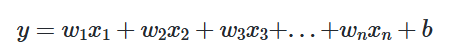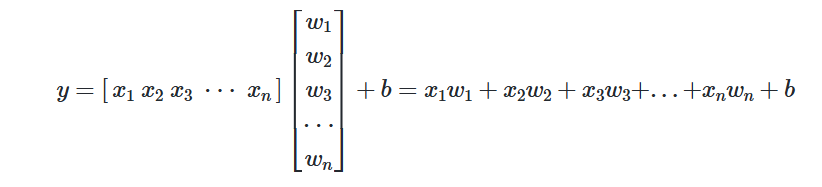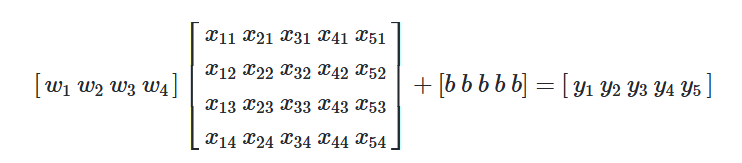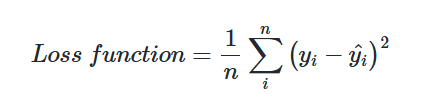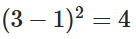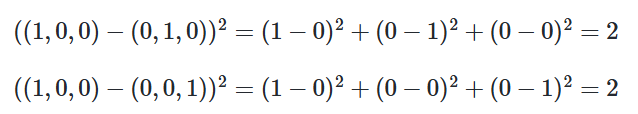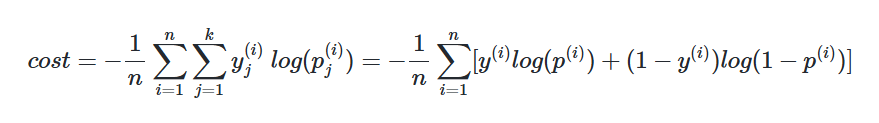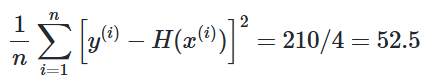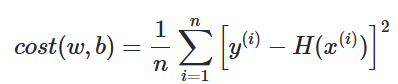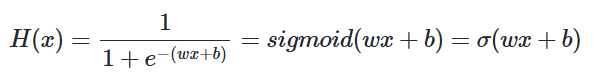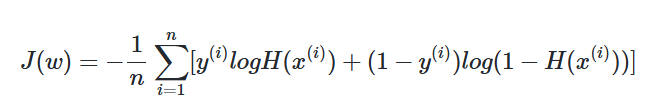퍼셉트론(Perceptron)은 프랑크 로젠블라트(Frank Rosenblatt)가 1957년에 제안한 초기 형태의인공 신경망으로 다수의 입력으로부터 하나의 결과를 내보내는 알고리즘입니다.
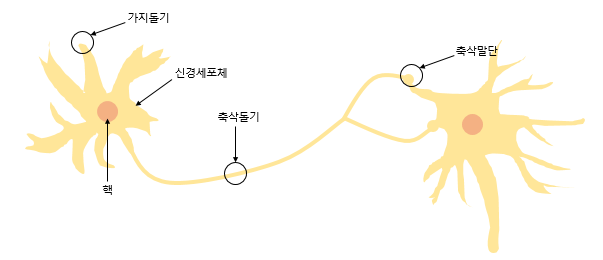
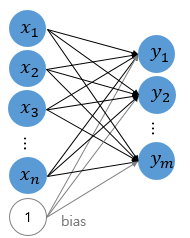
실제 뇌를 구성하는 신경 세포 뉴런의 동작과 유사한데, 신경 세포 뉴런의 그림을 먼저 보도록 하겠습니다. 뉴런은 가지돌기에서 신호를 받아들이고, 이 신호가 일정치 이상의 크기를 가지면 축삭돌기를 통해서 신호를 전달합니다.
다수의 입력을 받는 퍼셉트론의 그림을 보겠습니다. 신경 세포 뉴런의 입력 신호와 출력 신호가 퍼셉트론에서 각각 입력값과 출력값에 해당됩니다.각각의 입력값에는 각각의 가중치가 존재하는데, 이때가중치의 값이 크면 클수록 해당 입력 값이 중요하다는 것을 의미합니다.
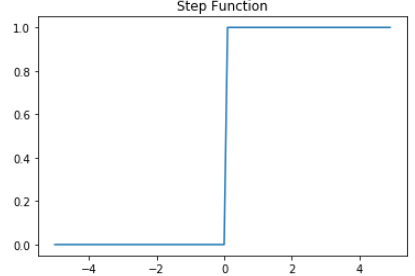
가중치의 곱의 전체 합이 임계치(threshold)를 넘으면 종착지에 있는 인공 뉴런은 출력 신호로서 1을 출력하고, 그렇지 않을 경우에는 0을 출력합니다.
📝단층 퍼셉트론(Single-Layer Perceptron)
위에서 배운 퍼셉트론을 단층 퍼셉트론이라고 합니다.퍼셉트론은 단층 퍼셉트론과 다층 퍼셉트론으로 나누어지는데, 단층 퍼셉트론은 값을 보내는 단계과 값을 받아서 출력하는 두 단계로만 이루어집니다.
이 각 단계를 보통 층(layer)이라고 부르며, 이 두 개의 층을입력층(input layer)과 출력층(output layer)입니다.
그렇기 때문에 복잡한 건 표현할 수 없습니다.
📝다층 퍼셉트론(MultiLayer Perceptron, MLP)
퍼셉트론 관점에서 말하면 층을 더 쌓으면 만들 수 있습니다. 다층 퍼셉트론과 단층 퍼셉트론의 차이는 단층 퍼셉트론은 입력층과 출력층만 존재하지만,다층 퍼셉트론은 중간에 층을 더 추가하였다는 점입니다. 이렇게 입력층과 출력층 사이에 존재하는 층을 은닉층(hidden layer)이라고 합니다.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
# 중간 고사, 기말 고사, 가산점 점수
X = np.array([[70,85,11], [71,89,18], [50,80,20], [99,20,10], [50,10,10]])
y = np.array([73, 82 ,72, 57, 34]) # 최종 성적
model = Sequential()
# 입력 차원 설정 (3으로 변경)
model.add(Dense(1, input_dim=3, activation='linear'))
sgd = optimizers.SGD(learning_rate=0.0001)
model.compile(optimizer=sgd, loss='mse', metrics=['mse'])
model.fit(X, y, epochs=2000)
print(model.predict(X))
X_test = np.array([[20,99,10], [40,50,20]])
print(model.predict(X_test))
📝2개 이상 변수 로지스틱 회귀
y를 결정하는데 있어 독립 변수 x가 2개인 로지스틱 회귀를 풀어봅시다. 꽃받침(Sepal)의 길이와 꽃잎(Petal)의 길이와 해당 꽃이 A인지 B인지가 적혀져 있는 데이터가 있을 때, 새로 조사한 꽃받침의 길이와 꽃잎의 길이로부터 무슨 꽃인지 예측할 수 있는 모델을 만들고자 한다면 이때 독립 변수x는 2개가 됩니다.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
X = np.array([[0, 0], [0, 1], [1, 0], [0, 2], [1, 1], [2, 0]])
y = np.array([0, 0, 0, 1, 1, 1])
model = Sequential()
model.add(Dense(1, input_dim=2, activation='sigmoid'))
model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['binary_accuracy'])
model.fit(X, y, epochs=2000)
print(model.predict(X))
# [
# [0.15245897]
# [0.4477718 ]
# [0.43305928]
# [0.7851759 ]
# [0.7749343 ]
# [0.764351 ]
# ]
다중 로지스틱 회귀를 인공 신경망의 형태로 표현하면 다음과 같습니다. 아직 인공 신경망을 배우지 않았음에도 이렇게 다이어그램으로 표현해보는 이유는 로지스틱 회귀를 일종의 인공 신경망 구조로 해석해도 무방함을 보여주기 위함입니다.
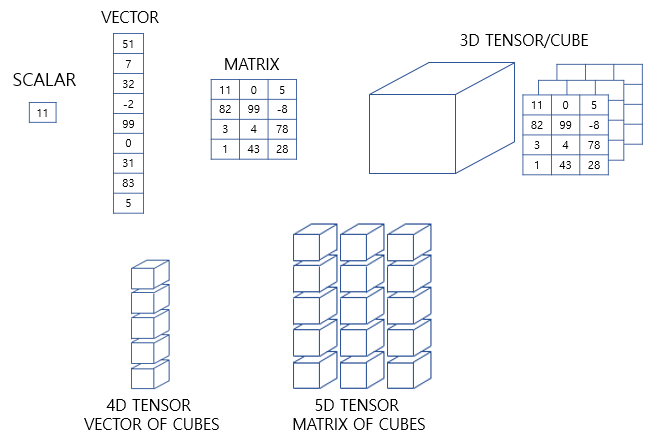
📝텐서, 벡터
1차원은 배열 또는 리스트로 표현합니다. 반면, 행렬은 행과 열을 가지는 2차원 형상을 가진 구조입니다. 파이썬에서는 2차원 배열로 표현합니다. 가로줄을 행(row)라고 하며, 세로줄을 열(column)이라고 합니다. 3차원부터는 주로 텐서라고 부릅니다. 텐서는 파이썬에서는 3차원 이상의 배열로 표현합니다.
벡터는 1차원 텐서입니다. 주의할 점은 벡터에서도 차원이라는 용어를 쓰는데, 벡터의 차원과 텐서의 차원은 다른 개념이라는 점입니다. 위 예제는 4차원 벡터이지만, 1차원 텐서입니다. 1D 텐서라고도 합니다. 참고로 벡터는 1차 텐서에서만 쓰이는 말입니다. → [1,2,3] 일 경우 3차원 벡터이며 x,y,z좌표로 표현한 거라 생각하면 된다.
0차원 ~ 2차원 텐서는 각각 스칼라, 벡터, 행렬이라고 해도 무방하므로 3차원 이상의 텐서부터 본격적으로 텐서라고 부릅니다. 데이터 사이언스 분야 한정으로 주로 3차원 이상의 배열을 텐서라고 부른다고 이해해도 좋습니다.이 3차원 텐서의 구조를 이해하지 않으면, 복잡한 인공 신경망의 입, 출력값을 이해하는 것이 쉽지 않습니다. 개념 자체는 어렵지 않지만 반드시 알아야하는 개념입니다.
3차원 텐서를 활용한 예제는 나중에 RNN을 배울텐데 그걸 이용해 대략적으로 알려드리면 아래와 같습니다.
컴퓨터는 이진수로 처리가능하기 때문에 이렇게 문자로 주어지면 모릅니다. 그리고 각 단어가 어떤 유사성을 가지고 있는지도 모르지만 이거를 원-핫 벡터를 이용해 벡터로 표현하면 위와 같고 (3,3,6)의 크기를 가지는 3D 텐서가 만들어집니다.
텐서 시각적 표현
📝벡터 덧셈과 뺄셈
A = np.array([8, 4, 5])
B = np.array([1, 2, 3])
print('두 벡터의 합 :',A+B)
print('두 벡터의 차 :',A-B)
# 두 벡터의 합 : [9 6 8]
# 두 벡터의 차 : [7 2 2]
📝행렬 덧셈과 뺄셈
A = np.array([[10, 20, 30, 40], [50, 60, 70, 80]])
B = np.array([[5, 6, 7, 8],[1, 2, 3, 4]])
print('두 행렬의 합 :')
print(A + B)
print('두 행렬의 차 :')
print(A - B)
# 두 행렬의 합 :
# [[15 26 37 48]
# [51 62 73 84]]
# 두 행렬의 차 :
# [[ 5 14 23 32]
# [49 58 67 76]]
📝벡터의 내적
A = np.array([1, 2, 3])
B = np.array([4, 5, 6])
print('두 벡터의 내적 :',np.dot(A, B))
# 두 벡터의 내적 : 32
📝행렬의 곱셈
A = np.array([[1, 3],[2, 4]])
B = np.array([[5, 7],[6, 8]])
print('두 행렬의 행렬곱 :')
print(np.matmul(A, B))
# 두 행렬의 행렬곱 :
# [[23 31]
# [34 46]]
📝다중선형 회귀 행렬 연산으로 이해하기
다중 선형 회귀
다중 선형 회귀 행렬 표현
다중 선형 회귀식을 행렬로 표현이 가능하다. 왜 이렇게 할까?
기본적으로 가독성이 좋아진다.
벡터화된 계산은 컴퓨터가 빨리 처리할 수 있습니다.
반복문 없이 한줄로 처리가 가능합니다.
# 내적 사용
import numpy as np
x = np.array([1.2, 0.7, 3.1])
w = np.array([0.5, 2.1, -1.3])
b = 0.2
y = np.dot(w, x) + b
# 내적 사용하지 않은 코드 (반복문)
x = [1.2, 0.7, 3.1]
w = [0.5, 2.1, -1.3]
b = 0.2
y = 0
for i in range(len(x)):
y += w[i] * x[i]
y += b
행렬 연산 예제
size(feet2)(x1)
number of bedrooms(x2)
number of floors(x3)
age of home(x4)
price($1000)(y)
1800
2
1
10
207
1200
4
2
20
176
1700
3
2
15
213
1500
5
1
10
234
1100
2
2
10
155
가중치와 입력값을 곱하고 절편값 b를 더해 원하는 결과를 얻어낼 수 있습니다.
📝다중 클래스 분류(Multi-class Classification)
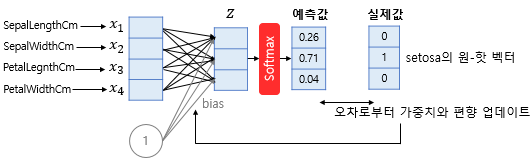
이진 분류가 두 개의 선택지 중 하나를 고르는 문제였다면, 세 개 이상의 선택지 중 하나를 고르는 문제를 다중 클래스 분류라고 합니다. 아래의 붓꽃 품종 예측 데이터는 꽃받침 길이, 꽃받침 넓이, 꽃잎 길이, 꽃잎 넓이로부터 setosa, versicolor, virginica라는 3개의 품종 중 어떤 품종인지를 예측하는 문제를 위한 데이터로 전형적인 다중 클래스 분류 문제를 위한 데이터입니다.
📝소프트맥스 함수(Softmax function)
소프트맥스 함수는 선택해야 하는 선택지의 총 개수를 k라고 할 때, k차원의 벡터를 입력받아 각 클래스에 대한 확률을 추정합니다. 꽃에 대한 분류를 할 때 4가지의 입력값을 받고 각 꽃의 특징에 따른 가중치를 받으며 Softmax함수를 거치면 그걸 0~1사이에 값으로 변환시켜줍니다. 오차로 인한 가중치화 편향을 업데이트하며 꽃에 해당하는 원-핫 벡터로 변경합니다.
문제 사항이 두가지가 있습니다.
변수는 4개지만 예측 클래스는 3개인 경우 차원을 축소시켜야합니다.
예측값으로부터 실제값에 대한 오차를 수정해서 실제값하고 동일하게 만들어야합니다.
1) 차원축소
x1, x2, x3, x4는 꽃에 대한 입력값이면 Z에 해당하는 건 꽃에 대한 확률값입니다. 예를 들면 Z에 1번째 해당하는 부분은 개나리, 2번째는 장미, 3번째는 진달래 이런것인 거죠 그래서 각 꽃에 해당하는 가중치값이 존재합니다. 이걸 계산식으로 표현하면 아래와 같습니다.
x1w11 + x2w12 + x3w13+ x4w14 = z1
x1w21 + x2w22 + x3w23+ x4w24 = z2
x1w31 + x2w32 + x3w33+ x4w34 = z3
2) 오차 범위수정
실제 원-핫 벡터와 값이 유사하지만 다르기 때문에 맞추는 과정인 가중치와 편향 업데이트 과정을 거칩니다.
인공 신경망으로 소프트 맥스 함수를 표현하면 위와 같습니다.
📝정수인코딩 vs 원핫인코딩
바나나
0
토마토
1
사과
2
정수 인코딩은 배열의 인덱스 처럼 뭔가 의미 있는 숫자는 아니고 그냥 단지 순서입니다.
바나나
[1,0,0]
토마토
[0,1,0]
사과
[0,0,1]
원-핫 벡터의 경우 각 숫자들이 인덱스처럼 구분만 되는 것이 아니라 단어의 방향성을 부여하는 것으로 숫자와 크기가 의미가 있습니다.
오차 범위 수정을 위해 제곱오차를 이용했을 때 값이 다릅니다
즉, Banana과 Tomato 사이의 오차보다 Banana과 Apple의 오차가 더 큽니다. 이는 기계에게 Banana가 Apple보다는 Tomato에 더 가깝다는 정보를 주는 것과 다름없습니다.
시험 공부하는 시간을 늘리면 늘릴 수록 성적이 잘 나옵니다. 하루에 걷는 횟수를 늘릴 수록, 몸무게는 줄어듭니다. 집의 평수가 클수록, 집의 매매 가격은 비싼 경향이 있습니다. 이는 수학적으로 생각해보면 어떤 요인의 수치에 따라서 특정 요인의 수치가 영향을 받고있다고 말할 수 있습니다. 수학적인 표현을 써보면 어떤 변수의 값에 따라서 특정 변수의 값이 영향을 받고 있다고 볼 수 있습니다.
즉, 핵심은 어떤 데이터들로부터 상관관계를 함수로 표현하고 그 함수에 해당하는 가중치와 절편 값을 찾아가는 과정입니다. 그러면 어떠한 모르는 값이 들어가도 함수로 유추할 수 있죠
📝단순 선형회귀
단순 선형회귀의 경우 하나의 변수만 있는 경우를 의미합니다. 예를 들면 몸무게에 따른 키로 봤을 때 몸무게가 x값이 되는 거고 그에 따른 통계를 냈을 때 몸무게에 대한 영향은 w(가중치)를 갖게 됩니다. 절편의 값은 그에 따른 조정이 필요할 때 추가적으로 들어가게 됩니다.
즉, 독립 변수 x와 곱해지는 값 w를 머신 러닝에서는 가중치(weight), 별도로 더해지는 값 b를 편향(bias)이라고 합니다.
📝다중 선형회귀
집의 매매 가격은 단순히 집의 평수가 크다고 결정되는 게 아니라 집의 층의 수, 방의 개수, 지하철 역과의 거리와도 영향이 있습니다. 이러한 다수의 요소를 가지고 집의 매매 가격을 예측해보고 싶습니다. y는 여전히 1개이지만 이제 x는 1개가 아니라 여러 개가 되었습니다. 즉, 다양한 요인들이 포함된 경우를 다중 선형 회귀 분석이라고 합니다.
📝목적함수, 비용함수, 손실함수
결국 w와 b를 잘 찾아내는게 목표입니다. w와 b를 찾기 위해서 실제값과 가설로부터 얻은 예측값의 오차를 계산하는 식을 세우고, 이 식의 값을 최소화하는 최적의 w와 b를 찾아냅니다.
실제값과 예측값에 대한 오차에 대한 식을목적 함수(Objective function) 또는 비용 함수(Cost function) 또는 손실 함수(Loss function)라고 합니다.
비용 함수는 단순히 실제값과 예측값에 대한 오차를 표현하면 되는 것이 아니라, 예측값의 오차를 줄이는 일에 최적화 된 식이어야 합니다.
손실함수 = (평균제곱오차)
실제값과 예측값을 비교하는 표가 있는데 오차는 = 실제값 - 예측값으로 모든 오차를 다 더하면 음수 오차도 있고 양수 오차도 있기 때문에 거리를 제곱하고 더한 후에 개수만큼 나눕니다.
더하는 과정전체로 나눠서 평균 구하는 과정
오차가 클수록 평균 제곱 오차는 커지며 작을수록 평균 제곱 오차는 작아집니다.
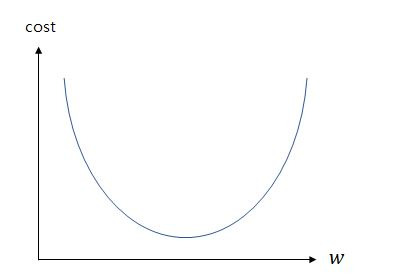
📝옵티마이저, 경사하강법
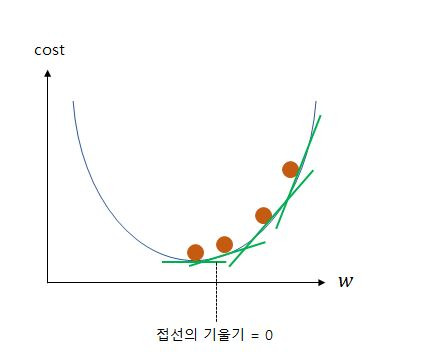
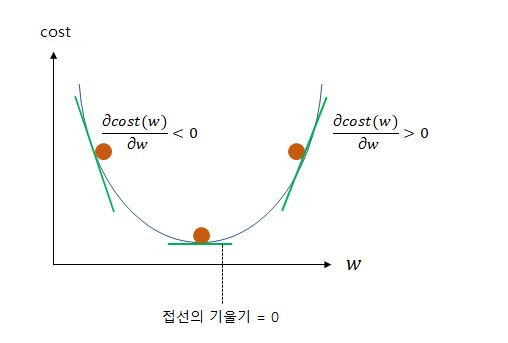
비용 함수를 최소화하기 위해 파라미터 조정하는 과정을 의미합니다. 위 그림은 가중치에 따른 손실함수의 값을 그래프로 만든것인데 cost가 가장 낮은 범위를 찾아야 가장 최적의 조건의 학습이 되는 것입니다. 위 그림을 보면 한눈에 w에따른 cost값을 알수 있지만 전부 다 저렇게 알 수 있지 않습니다.
그렇기 때문에 하나하나씩 차근차근 경사 하강법을 이용해 미분해서 기울기 값이 가장 작아지는 경우를 찾아가는 겁니다.
📝선형회귀 실습
import tensorflow as tf
# tf.Variable은 변수에 대한 값을 지정할 때 사용 (가중치와 절편에 값 지정)
w = tf.Variable(4.0)
b = tf.Variable(1.0)
# w*x + b 형태의 선형회귀함수를 가진다.
@tf.function
def hypothesis(x):
return w*x + b
# 손실함수 (제곱오차의 평균)
@tf.function
def mse_loss(y_pred, y):
# 두 개의 차이값을 제곱을 해서 평균을 취한다.
return tf.reduce_mean(tf.square(y_pred - y))
x = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 공부하는 시간
y = [11, 22, 33, 44, 53, 66, 77, 87, 95] # 각 공부하는 시간에 맵핑되는 성적
# 경사 하강법을 이용하며 0.01 정도로 하강하며 적용
optimizer = tf.optimizers.SGD(0.01)
# 300번을 순회하며 처음 설정한 w, b값을 기준으로 선형회귀함수를 가지는 걸 제곱오차로 따져서 경사 하강법을 적용시키며 최적의 cost값을 찾는 과정
for i in range(301):
with tf.GradientTape() as tape:
# 현재 파라미터에 기반한 입력 x에 대한 예측값을 y_pred
y_pred = hypothesis(x)
# 평균 제곱 오차를 계산 (예측값과 실제값 비교)
cost = mse_loss(y_pred, y)
# 손실 함수에 대한 파라미터의 미분값 계산
gradients = tape.gradient(cost, [w, b])
# 경사하강법에 나온 w와 b값을 조정하며 파라미터 업데이트
optimizer.apply_gradients(zip(gradients, [w, b]))
# 10번 루프마다 체크
if i % 10 == 0:
print("epoch : {:3} | w의 값 : {:5.4f} | b의 값 : {:5.4} | cost : {:5.6f}".format(i, w.numpy(), b.numpy(), cost))
Tensorflow로 직접 구현하기
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
x = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 공부하는 시간
y = [11, 22, 33, 44, 53, 66, 77, 87, 95] # 각 공부하는 시간에 맵핑되는 성적
model = Sequential()
# 출력 y의 차원은 1. 입력 x의 차원(input_dim)은 1
# 선형 회귀이므로 activation은 'linear'
model.add(Dense(1, input_dim=1, activation='linear'))
# sgd는 경사 하강법을 의미. 학습률(learning rate, lr)은 0.01.
sgd = optimizers.SGD(lr=0.001)
# 손실 함수(Loss function)은 평균제곱오차 mse를 사용합니다.
model.compile(optimizer=sgd, loss='mse', metrics=['mse'])
# 주어진 x와 y데이터에 대해서 오차를 최소화하는 작업을 300번 시도합니다.
model.fit(x, y, epochs=300)
plt.plot(x, model.predict(x), 'b', x, y, 'k.')
plt.show()
# 8.5시간 공부했을 때 성적 예측하기
print(model.predict([9.5]))
# [[89.20797]]
Keras로 구현해보기
로직에 대해서 대충 파악하고 이미 잘 만들어진 Keras를 이용하는게 좋긴합니다.
📝이진 분류 (로지스틱 회귀)
둘 중 하나를 결정하는 문제를 이진 분류(Binary Classification)라고 합니다. 그리고 이런 문제를 풀기 위한 대표적인 알고리즘으로 로지스틱 회귀(Logistic Regression)가 있습니다
score(x)
result(y)
45
불합격
50
불합격
55
불합격
60
합격
65
합격
70
합격
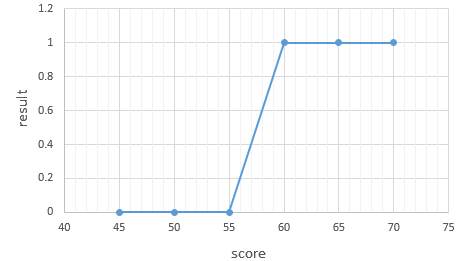
위 데이터에서 합격을 1, 불합격을 0이라고 하였을 때 그래프를 그려보면 아래와 같습니다.
그래프는 알파벳의 S자 형태로 표현됩니다. 이러한 x와 y의 관계를 표현하기 위해서는 직선을 표현하는 함수가 아니라 S자 형태로 표현할 수 있는 함수가 필요합니다.
레이블에 해당하는y가 0 또는 1이라는 두 가지 값만을 가지므로, 이 문제를 풀기 위해서 예측값은 0과 1사이의 값을 가지도록 합니다. 0과 1사이의 값을 확률로 해석하면 문제를 풀기가 훨씬 용이해집니다. 최종 예측값이 0.5보다 작으면 0으로 예측했다고 판단하고, 0.5보다 크면 1로 예측했다고 판단합니다.
출력이 0과 1사이의 값을 가지면서 S자 형태로 그려지는 함수로 시그모이드 함수(Sigmoid function)가 있습니다.
📝시그모이드 함수(Sigmoid function)
시그모이드 함수는 종종 σ로 축약해서 표현하기도 합니다. 해당 함수는 위와 같이 함수를 표현하는 함수인 것이고 인공지능이 찾아야할 건결국 w와 b입니다.
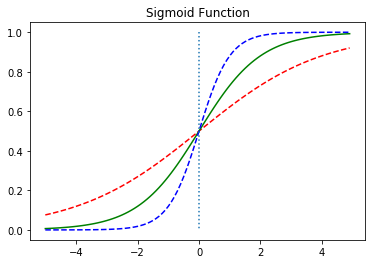
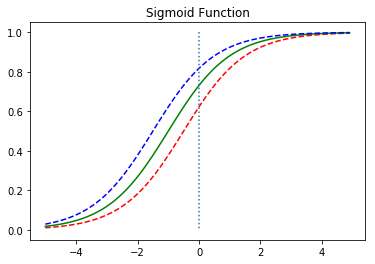
w변화에 따른 함수 변화 b에 따른 함수 변화
📝로지스틱 손실함수(크로스 엔트로피함수)
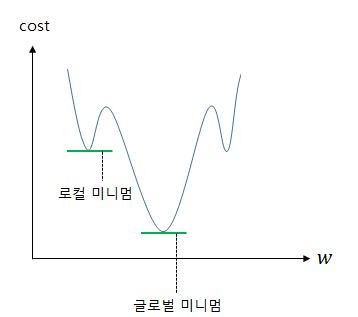
로지스틱 회귀에서 평균 제곱 오차를 비용 함수로 사용하면, 경사 하강법을 사용하였을때 찾고자 하는 최소값이 아닌 잘못된 최소값에 빠질 가능성이 매우 높습니다. 이를 전체 함수에 걸쳐 최소값인글로벌 미니멈(Global Minimum)이 아닌 특정 구역에서의 최소값인로컬 미니멈(Local Minimum)에 도달했다고 합니다. 로컬 미니멈에 지나치게 쉽게 빠지는 비용 함수는 cost가 가능한한 최소가 되는 가중치w를 찾는다는 목적에는 좋지 않은 선택입니니다. 그리고 로지스틱 회귀에서의 평균 제곱 오차는 바로 그 좋지 않은 선택에 해당합니다.
여러가지 계산을 거쳐서 나온 손실함수인데 그 과정을 완전히 무에서 유추하는 거는 솔직히 의미없는 것 같습니다. (사실 안 해봐서 잘 모름)로지스틱 회귀에서 찾아낸 비용 함수를 크로스 엔트로피(Cross Entropy)함수라고 합니다.
사진이란 건 사진을 보는 각도, 조명, 타겟의 변형(고양이의 자세)에 따라서 너무나 천차만별이라 사진으로부터 공통된 명확한 특징을 잡아내는 것이 쉽지 않습니다. 사실, 결론을 미리 말씀드리면 해당 프로그램은 숫자를 정렬하는 것과 같은 명확한 알고리즘이 애초에 존재하지 않습니다. 머신 러닝은 데이터가 주어지면, 기계가 스스로 데이터로부터 규칙성을 찾는 것에 집중합니다. 주어진 데이터로부터 규칙성을 찾는 과정을 우리는 훈련(training) 또는 학습(learning)이라고 합니다.
📝하이퍼파라미터 (초매개변수) vs 매개변수
하이퍼파라미터(초매개변수)
사람이 값을 지정하는 변수로 모델의 성능에 영향을 준다. 학습 전에 미리 설정되며 학습률, 배치 크기, 에포크, 레이어수 등이 있다.
매개변수
가중치와 편향과 같은 매개변수는 사용자가 결정해주는 값이 아니라 모델이 학습하는 과정에서 얻어지는 값입니다. 즉, 학습을 하는 동안 값이 계속해서 변하는 수입니다.
📝분류(Classification)와 회귀(Regression)
전부는 아니지만 머신 러닝의 많은 문제는 분류 또는 회귀 문제에 속합니다.
이진 분류 문제
두개의 선택지 중 하나의 답을 선택해야하는 경우를 말합니다.
예) 어떤 학생이 과학, 수학 중에 어떤 걸 좋아할까?
다중 클래스 분류
세개 이상의 선택지중에서 답을 선택하는 경우를 말합니다.
예) 어떤 학생이 과학, 수학, 영어 중에 어떤 걸 좋아할까?
회귀 문제
둘중에 하나를 선택하는 것이 아닌 예측값을 찾아내는 역할을 합니다.
예) 사람이 190cm이면서 다른 여러 조건이 주어졌을 때 이 사람의 몸무게는 얼마일까?
📝지도 학습, 비지도 학습, 자기지도 학습
지도 학습
레이블과 정답을 이용해 학습하는 걸 의미합니다.
비지도 학습
별도의 레이블 없이 학습하는 걸 의미합니다.
자기지도 학습
모델이 학습하기 위해 스스로 데이터로부터 레이블을 만들어서 학습하는 경우를 의미합니다.
📝샘플, 특성
샘플과 특성이라는 말을 많이 사용하는데 샘플이란 하나의 시험체를 의미한다. 예를 들면 A라는 생선이 있으면 A라는 생선은 Sample1이 되는 것이고 눈이 2개이다. 입이 1개이다. 코가 없다. 이런 것들이 각각 특성이 되는 것이다.
📝과적합(Overfitting), 과소 적합 (Underfitting)
과적합
과적합의 경우 훈련 데이터를 너무 과하게 학습해서 실제 그 외 데이터에 대해서는 맞추지 못합니다.
과소적합
과소 적합의 경우 그 반대로 너무 훈련 데이터를 제대로 학습 안 해서 훈련 자체가 부족한 상황을 의미합니다.
언어 모델을 만드는 방법은 크게는 통계를 이용한 방법과 인공 신경망을 이용한 방법으로 구분할 수 있습니다.
최근에는 통계를 이용한 방법보다는 인공 신경망을 이용한 방법이 더 좋은 성능을 보여주고 있습니다.
📝언어 모델 종류
통계적 언어 모델 (SLM)
말 그대로 통계를 내어서 확률적으로 다음 언어를 유추하는 방법입니다. 수학에 가장 유사한 것으로는 조건부확률이 있습니다. 해당 모델의 문제점으로는 통계에 들어가지 않는 데이터는 추가적인 기법을 적용하지 않는 이 영원히 나오지 않습니다.
N-gram 언어 모델
SLM의 경우는 모든 데이터를 카운트하면서 유추하지만 N-gram의 경우 문장을 N개 단위로 나누어 분석하며, 빠르고 적은 데이터로도 학습 가능하지만 긴 문맥을 반영하지 못한다. 정밀한 단계에서는 SLM에 비해 빈약하며 SLM처럼 통계에 들어가지 않는 데이터는 추가적인 기법을 적용하지 않는 이 영원히 나오지 않습니다.
한국어 언어 모델
한국어의 경우 띄어쓰기 단위로 토큰화하면 문제가 발생할 수 있어서 토큰화가 중요하며 어순이 중요하지 않고 띄어쓰기가 제대로 이루어지지도 않기 때문에 어렵다.
📝언어 모델 평가 (PPL)
어떤 언어 모델이 정확하지 평가하기 위한 지표이다.
📝단어 표현 방식
단어의 표현 방법은 크게 국소 표현(Local Representation) 방법과 분산 표현(Distributed Representation) 방법으로 나뉩니다. 국소 표현 방법은 해당 단어 그 자체만 보고, 특정값을 맵핑하여 단어를 표현하는 방법이며, 분산 표현 방법은 그 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법입니다.
예를 들어 puppy(강아지), cute(귀여운), lovely(사랑스러운)라는 단어가 있을 때 각 단어에 1번, 2번, 3번 등과 같은 숫자를 맵핑(mapping)하여 부여한다면 이는 국소 표현 방법에 해당됩니다. 반면, 분산 표현 방법의 예를 하나 들어보면 해당 단어를 표현하기 위해 주변 단어를 참고합니다. puppy(강아지)라는 단어 근처에는 주로 cute(귀여운), lovely(사랑스러운)이라는 단어가 자주 등장하므로, puppy라는 단어는 cute, lovely한 느낌이다로 단어를 정의합니다
Bag of Words
단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법입니다. Bag of Words를 직역하면 단어들의 가방이라는 의미입니다
from konlpy.tag import Okt
okt = Okt()
def build_bag_of_words(document):
# 온점 제거 및 형태소 분석
document = document.replace('.', '')
tokenized_document = okt.morphs(document)
word_to_index = {}
bow = []
for word in tokenized_document:
if word not in word_to_index.keys():
word_to_index[word] = len(word_to_index)
# BoW에 전부 기본값 1을 넣는다.
bow.insert(len(word_to_index) - 1, 1)
else:
# 재등장하는 단어의 인덱스
index = word_to_index.get(word)
# 재등장한 단어는 해당하는 인덱스의 위치에 1을 더한다.
bow[index] = bow[index] + 1
return word_to_index, bow
doc1 = "정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다."
vocab, bow = build_bag_of_words(doc1)
print('vocabulary :', vocab)
# vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}
print('bag of words vector :', bow)
# bag of words vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]
단어에 번호를 매긴 후에 얼마나 빈도수가 있는지를 추가 시킵니다.
문서 단어 행렬(Document-Term Matrix, DTM)
문서 단어 행렬(Document-Term Matrix, DTM)이란 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것을 말합니다. 쉽게 생각하면 각 문서에 대한 BoW를 하나의 행렬로 만든 것으로 생각할 수 있으며, BoW와 다른 표현 방법이 아니라 BoW 표현을 다수의 문서에 대해서 행렬로 표현하고 부르는 용어입니다.
문서1 : 먹고 싶은 사과 문서2 : 먹고 싶은 바나나 문서3 : 길고 노란 바나나 바나나 문서4 : 저는 과일이 좋아요
과일이
길고
노란
먹고
바나나
사과
싶은
저는
좋아요
문서1
0
0
0
1
0
1
1
0
0
문서2
0
0
0
1
1
0
1
0
0
문서3
0
1
1
0
2
0
0
0
0
문서4
1
0
0
0
0
0
0
1
1
위 예시를 DTM으로 변환시켰을때는 해당 표와 같습니다. 이렇게 하는 경우 원-핫 인코딩처럼 필요 없는 공간 차지가 존재하게 됩니다. 또한 영어에서는 The가 많이 나오는데 The가 중요한 단어는 아니기 때문에 이에 대한 처리가 필요합니다.
TF-IDF(단어 빈도-역 문서 빈도, Term Frequency-Inverse Document Frequency)
이번에는 DTM 내에 있는 각 단어에 대한 중요도를 계산할 수 있는 TF-IDF 가중치에 대해서 알아보겠습니다. TF-IDF를 사용하면, 기존의 DTM을 사용하는 것보다 보다 많은 정보를 고려하여 문서들을 비교할 수 있습니다. TF-IDF가 DTM보다 항상 좋은 성능을 보장하는 것은 아니지만, 많은 경우에서 DTM보다 더 좋은 성능을 얻을 수 있습니다.
tf(d,t)
특정 문서 d에서의 특정 단어 t의 등장 횟수
df(t)
특정 단어 t가 등장한 문서의 수
idf(t)
df(t)에 반비례하는 수로 log(n1+df(t))라는 수식을 사용해서 만드는데 문서 n이 커질수록 기하급수적으로 커지기 때문에 log를 이용합니다.
from math import log # IDF 계산을 위해
import pandas as pd # 데이터프레임 사용을 위해
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort()
# 총 문서의 수
N = len(docs)
def tf(t, d):
return d.count(t)
def idf(t):
df = 0
for doc in docs:
df += t in doc
return log(N / (df + 1))
def tfidf(t, d):
return tf(t, d) * idf(t)
result = []
# 각 문서에 대해서 아래 연산을 반복
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tf(t, d))
tf_ = pd.DataFrame(result, columns=vocab)
print(tf_)
# 과일이 길고 노란 먹고 바나나 사과 싶은 저는 좋아요
# 0 0 0 0 1 0 1 1 0 0
# 1 0 0 0 1 1 0 1 0 0
# 2 0 1 1 0 2 0 0 0 0
# 3 1 0 0 0 0 0 0 1 1
result = []
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tfidf(t, d))
tfidf_ = pd.DataFrame(result, columns=vocab)
print(tfidf_)
# 과일이 길고 노란 ... 싶은 저는 좋아요
# 0 0.000000 0.000000 0.000000 ... 0.287682 0.000000 0.000000
# 1 0.000000 0.000000 0.000000 ... 0.287682 0.000000 0.000000
# 2 0.000000 0.693147 0.693147 ... 0.000000 0.000000 0.000000
# 3 0.693147 0.000000 0.000000 ... 0.000000 0.693147 0.693147
직접 코드로 구현한 부분이긴 하지만 라이브러리 제공하니까 그걸로 사용하면 됩니다.
코사인 유사도(Cosine Similarity)
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미합니다. 두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 됩니다. 즉, 결국 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있습니다. 이를 직관적
으로 이해하면 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미합니다.
여기에서 벡터가 의미하는 건 문장이나 문서를 벡터(방향과 크기)로 변환시켜서 나타내는 것입니다. 그래서 해당 문서끼리 얼마나 같은 방향에 있냐 이정도로 유사도를 따질 수 있습니다.
데이터를 점검하고 탐색하는 단계입니다. 여기서는 데이터의 구조, 노이즈 데이터, 머신 러닝 적용을 위해서 데이터를 어떻게 정제해야하는지 등을 파악해야 합니다.
3) 전처리 및 정제(Preprocessing and Cleaning)
데이터에 대한 파악이 끝났다면, 머신 러닝 워크플로우에서 가장 까다로운 작업 중 하나인 데이터 전처리 과정에 들어갑니다.
4) 모델링 및 훈련(Modeling and Training)
머신 러닝에 대한 코드를 작성하는 단계인 모델링 단계에 들어갑니다. 적절한 머신 러닝 알고리즘을 선택하여 모델링이 끝났다면, 전처리가 완료 된 데이터를 머신 러닝 알고리즘을 통해 기계에게 학습(training)시킵니다. 여기서 주의해야 할 점은 대부분의 경우에서 모든 데이터를 기계에게 학습시켜서는 안 된다는 점입니다. 데이터 중 일부는 테스트용으로 남겨두고 훈련용 데이터만 훈련에 사용해야 합니다. 그래야만 기계가 학습을 하고나서, 테스트용 데이터를 통해서 현재 성능이 얼마나 되는지를 측정할 수 있으며 과적합(overfitting) 상황을 막을 수 있습니다. 사실 최선은 훈련용, 테스트용으로 두 가지만 나누는 것보다는 훈련용, 검증용, 테스트용. 데이터를 이렇게 세 가지로 나누고 훈련용 데이터만 훈련에 사용하는 것입니다.
5) 평가(Evaluation)
기계가 다 학습이 되었다면 테스트용 데이터로 성능을 평가하게 됩니다. 평가 방법은 기계가 예측한 데이터가 테스트용 데이터의 실제 정답과 얼마나 가까운지를 측정합니다.
6) 배포(Deployment)
성공적으로 훈련이 된 것으로 판단된다면 완성된 모델이 배포되는 단계가 됩니다.
훈련용 vs 검증용 vs 테스트용?
수능 시험에 비유하자면 훈련용은 학습지, 검증용은 모의고사, 테스트용은 수능 시험이라고 볼 수 있습니다. 학습지를 풀고 수능 시험을 볼 수도 있겠지만, 모의 고사를 풀며 부족한 부분이 무엇인지 검증하고 보완하는 단계를 하나 더 놓는 방법도 있겠지요. 사실 현업의 경우라면 검증용 데이터는 거의 필수적입니다. 모델의 성능을 수치화하여 평가하기 위해 사용됩니다. 쉽게 말해 시험에 비유하면 채점하는 단계입니다.
📝 단어 토큰화(Word Tokenization)
토큰화의 경우 문장을 의미를 갖는 단어로 쪼개는 과정을 의미합니다. 보통 토큰화 작업에는 특수문자나 구두점 등을 제거하는 작업만으로는 충분하지 않습니다. 제거함으로 그 의미를 잃어버리는 경우가 있기 때문이고 띄어쓰기로 사용하는 경우는 영어의 경우는 괜찮지만 한국어는 구분하기 어렵습니다. 또한 한국어는 띄어쓰기가 잘 지켜지지 않습니다.
구두점, 특수문자 제외 예외상황
Ph.D, 12/45 (12시 45분)
줄임말과 단어 내에 띄어쓰기가 있는 예외상황
New York
📝품사태깅
단어는 표기는 같지만 품사에 따라서 단어의 의미가 달라지기도 합니다. 예를 들어서 영어 단어 'fly'는 동사로는 '날다'라는 의미를 갖지만, 명사로는 '파리'라는 의미를 갖고있습니다. 한국어도 마찬가지입니다.
📝토큰화 작업 전 정제 및 정규화
토큰화 작업 전, 후에는 텍스트 데이터를 용도에 맞게 정제(cleaning) 및 정규화(normalization)하는 일이 항상 함께합니다.
정제(cleaning)
갖고 있는 코퍼스로부터 노이즈 데이터를 제거한다.
정규화(normalization)
표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어준다
📝정제 및 정규화
규칙에 기반한 표기가 다른 단어들의 통합
USA와 US는 같은 의미를 가지므로 하나의 단어로 정규화해볼 수 있습니다
대, 소문자 통합
영어에서의 대,소문자 통합이 있다. (하지만 예외도 존재 us와 US의 차이)
불필요한 단어의 제거
아무 의미도 갖지 않는 글자들(특수 문자 등)을 의미하기도 하지만, 분석하고자 하는 목적에 맞지 않는 불필요 단어들을 노이즈 데이터라고 하기도 합니다. 일반적으로 불필요 단어들을 제거하는 방법으로는 불용어 제거와 등장 빈도가 적은 단어, 길이가 짧은 단어들을 제거하는 방법이 있습니다.
등장 빈도가 적은 단어와 길이가 짧은 단어가 있다. 등장 빈도가 낮은 경우 너무 적게 등장해서 자연어 처리에 도움이 되지 않는 단어를 의미하며 길이가 짧은 단어의 경우는 영어권에서 일반적으로 짧은 단어일수록 의미가 없는 경우가 매우 많다.
표제어 추출
서로 다른 단어들이지만, 하나의 단어로 일반화시킬 수 있다면 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이겠다는 것입니다. 이러한 정규화의 지향점은 언제나 갖고 있는 코퍼스로부터 복잡성을 줄이는 일입니다. 예를 들면 "맛있는" → "맛있다"에서 파생된 단어로서 "맛있겠다"도 같은 의미를 가지고 있습니다.
불용어
갖고 있는 데이터에서 유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰을 제거하는 작업이 필요합니다. 여기서 큰 의미가 없다라는 것은 자주 등장하지만 분석을 하는 것에 있어서는 큰 도움이 되지 않는 단어들을 말합니다. 예를 들면, I, my, me, over, 조사, 접미사 같은 단어들은 문장에서는 자주 등장하지만 실제 의미 분석을 하는데는 거의 기여하는 바가 없는 경우가 있습니다.
패딩
아래에서 설명
📝원핫인코딩
원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식입니다. 이렇게 표현된 벡터를원-핫 벡터(One-Hot vector)라고 합니다.
from konlpy.tag import Okt
def one_hot_encoding(word, word_to_index):
one_hot_vector = [0] * (len(word_to_index))
index = word_to_index[word]
one_hot_vector[index] = 1
return one_hot_vector
okt = Okt()
tokens = okt.morphs("나는 자연어 처리를 배운다")
print(tokens)
# ['나', '는', '자연어', '처리', '를', '배운다']
word_to_index = {
word: index for index, word in enumerate(tokens)
}
print('단어 집합 :', word_to_index)
# 단어 집합 : {'나': 0, '는': 1, '자연어': 2, '처리': 3, '를': 4, '배운다': 5}
result = one_hot_encoding("자연어", word_to_index)
print(result)
# [0, 0, 1, 0, 0, 0]
직접 함수를 정의해서 보여줬지만 제공하는 라이브러리의 함수를 사용 할 수도 있습니다.
이러한 표현 방식은 단어의 개수가 늘어날 수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어난다는 단점이 있습니다. 다른 표현으로는 벡터의 차원이 늘어난다고 표현합니다. 원 핫 벡터는 단어 집합의 크기가 곧 벡터의 차원 수가 됩니다. 가령, 단어가 1,000개인 코퍼스를 가지고 원 핫 벡터를 만들면, 모든 단어 각각은 모두 1,000개의 차원을 가진 벡터가 됩니다. 다시 말해 모든 단어 각각은 하나의 값만 1을 가지고, 999개의 값은 0의 값을 가지는 벡터가 되는데 이는 저장 공간 측면에서는 매우 비효율적인 표현 방법입니다.
자연어 처리를 하다보면 각 문장(또는 문서)은 서로 길이가 다를 수 있습니다. 그런데 기계는 길이가 전부 동일한 문서들에 대해서는 하나의 행렬로 보고, 한꺼번에 묶어서 처리할 수 있습니다. 다시 말해 병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업이 필요할 때가 있습니다. 길이가 7보다 짧은 문장에는 전부 숫자 0이 뒤로 붙어서 모든 문장의 길이가 전부 7로 맞춥니다. 이것을 0으로 채웠기 때문에 제로 패딩이라고 합니다.
인코딩을 하는 궁극적인 이유는 컴퓨터에서 추후 처리를 위해 숫자로 변환시키는게 좋기 때문에 하는 작업이다.
import pandas as pd
# 리스트로 생성하기
data = [
['1000', 'Steve', 90.72],
['1001', 'James', 78.09],
['1002', 'Doyeon', 98.43],
['1003', 'Jane', 64.19],
['1004', 'Pilwoong', 81.30],
['1005', 'Tony', 99.14],
]
df = pd.DataFrame(data)
print(df)
'''
=== 출력 결과 ===
0 1 2
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
'''
df = pd.DataFrame(data, columns=['학번', '이름', '점수'])
print(df)
'''
=== 출력 결과 ===
학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
'''
딕셔너리 To 데이터프레임
# pip install pandas
import pandas as pd
# 딕셔너리로 생성하기
data = {
'학번' : ['1000', '1001', '1002', '1003', '1004', '1005'],
'이름' : [ 'Steve', 'James', 'Doyeon', 'Jane', 'Pilwoong', 'Tony'],
'점수': [90.72, 78.09, 98.43, 64.19, 81.30, 99.14]
}
df = pd.DataFrame(data)
print(df)
'''
=== 출력 결과 ===
학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
'''
데이터프레임 다양하게 출력해보기
import pandas as pd
data = {
'학번' : ['1000', '1001', '1002', '1003', '1004', '1005'],
'이름' : [ 'Steve', 'James', 'Doyeon', 'Jane', 'Pilwoong', 'Tony'],
'점수': [90.72, 78.09, 98.43, 64.19, 81.30, 99.14]
}
df = pd.DataFrame(data)
# 앞 부분을 3개만 보기
print(df.head(3))
'''
학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
'''
# 뒤 부분을 3개만 보기
print(df.tail(3))
'''
학번 이름 점수
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
'''
# 원하는 열만 보기
print(df['학번'])
'''
0 1000
1 1001
2 1002
3 1003
4 1004
5 1005
Name: 학번, dtype: object
'''
📝넘파이(Numpy)
넘파이(Numpy)는 수치 데이터를 다루는 파이썬 패키지입니다. Numpy의 핵심이라고 불리는 다차원 행렬 자료구조인 ndarray를 통해 벡터 및 행렬을 사용하는 선형 대수 계산에서 주로 사용됩니다. Numpy는 편의성뿐만 아니라, 속도면에서도 순수 파이썬에 비해 압도적으로 빠르다는 장점이 있습니다. → 계산에 이용
LLM을 활용한 애플리케이션을 쉽게 개발할 수 있도록 도와주는 프레임워크로 RAG를 구현하는 데 아주 유용한 도구입니다.
📝RAG (Retrieval-Augmented Generation)
RAG는 정보 검색 기반 생성 모델을 의미하며 아래 두 가지 프로세스를 결합한 구조입니다.
Retrieval(정보 검색)
외부 데이터베이스나 문서에서 필요한 정보를 검색
OpenAI GPT 같은 LLM이 기존에 학습하지 않은 최신 데이터나 특정 도메인 데이터를 활용할 수 있도록 함
Generation(생성)
검색된 정보를 기반으로 자연어 답변을 생성
RAG 작동 원리
질문 입력 → 사용자가 질문을 입력
정보 검색 → 검색 엔진이나 벡터 데이터베이스를 사용해 관련 정보를 검색
생성 단계 → 검색된 정보를 언어 모델에 전달하여 적합한 답변 생성
RAG의 장점
최신 정보나 사전 학습 데이터에 없는 데이터에 접근 가능
모델의 응답 정확도를 높이고 불필요한 "환각(hallucination)"을 줄임.
📝자연어
자연어(natural language)란 우리가 일상 생활에서 사용하는 언어를 말합니다. 자연어 처리(natural language processing)란 이러한 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일을 말합니다.
📝텐서플로우(Tensorflow)
텐서플로우는 구글이 2015년에 공개한 머신 러닝 오픈소스 라이브러리입니다. 머신 러닝과 딥러닝을 직관적이고 손쉽게 할 수 있도록 설계되었습니다.
📝케라스(Keras)
케라스(Keras)는 딥러닝 프레임워크인 텐서플로우에 대한 추상화 된 API를 제공합니다. 쉽게 말해, 텐서플로우 코드를 훨씬 간단하게 작성할 수 있습니다.
📝젠심(Gensim)
젠심(Gensim)은 머신 러닝을 사용하여 토픽 모델링과 자연어 처리 등을 수행할 수 있게 해주는 오픈 소스 라이브러리입니다.
📝사이킷런(Scikit-learn)
사이킷런(Scikit-learn)은 파이썬 머신러닝 라이브러리입니다. 사이킷런을 통해 나이브 베이즈 분류, 서포트 벡터 머신 등 다양한 머신 러닝 모듈을 불러올 수 있습니다. 또한, 사이킷런에는 머신러닝을 연습하기 위한 아이리스 데이터, 당뇨병 데이터 등 자체 데이터 또한 제공하고 있습니다.