LLM을 활용한 애플리케이션을 쉽게 개발할 수 있도록 도와주는 프레임워크로 RAG를 구현하는 데 아주 유용한 도구입니다.
📝RAG (Retrieval-Augmented Generation)
RAG는 정보 검색 기반 생성 모델을 의미하며 아래 두 가지 프로세스를 결합한 구조입니다.
Retrieval(정보 검색)
외부 데이터베이스나 문서에서 필요한 정보를 검색
OpenAI GPT 같은 LLM이 기존에 학습하지 않은 최신 데이터나 특정 도메인 데이터를 활용할 수 있도록 함
Generation(생성)
검색된 정보를 기반으로 자연어 답변을 생성
RAG 작동 원리
질문 입력 → 사용자가 질문을 입력
정보 검색 → 검색 엔진이나 벡터 데이터베이스를 사용해 관련 정보를 검색
생성 단계 → 검색된 정보를 언어 모델에 전달하여 적합한 답변 생성
RAG의 장점
최신 정보나 사전 학습 데이터에 없는 데이터에 접근 가능
모델의 응답 정확도를 높이고 불필요한 "환각(hallucination)"을 줄임.
📝자연어
자연어(natural language)란 우리가 일상 생활에서 사용하는 언어를 말합니다. 자연어 처리(natural language processing)란 이러한 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일을 말합니다.
📝텐서플로우(Tensorflow)
텐서플로우는 구글이 2015년에 공개한 머신 러닝 오픈소스 라이브러리입니다. 머신 러닝과 딥러닝을 직관적이고 손쉽게 할 수 있도록 설계되었습니다.
📝케라스(Keras)
케라스(Keras)는 딥러닝 프레임워크인 텐서플로우에 대한 추상화 된 API를 제공합니다. 쉽게 말해, 텐서플로우 코드를 훨씬 간단하게 작성할 수 있습니다.
📝젠심(Gensim)
젠심(Gensim)은 머신 러닝을 사용하여 토픽 모델링과 자연어 처리 등을 수행할 수 있게 해주는 오픈 소스 라이브러리입니다.
📝사이킷런(Scikit-learn)
사이킷런(Scikit-learn)은 파이썬 머신러닝 라이브러리입니다. 사이킷런을 통해 나이브 베이즈 분류, 서포트 벡터 머신 등 다양한 머신 러닝 모듈을 불러올 수 있습니다. 또한, 사이킷런에는 머신러닝을 연습하기 위한 아이리스 데이터, 당뇨병 데이터 등 자체 데이터 또한 제공하고 있습니다.
전통적인 컴퓨터가 사용하는 비트(bit) 대신, 양자 컴퓨터는 양자 비트(큐비트, qubit)를 사용해 정보를 처리합니다.
큐비트는 0과 1 사이의 모든 상태를 동시에 가질 수 있습니다.
예를들면 3개의 고전 비트는 한 번에 하나의 상태(예: 000, 001, ... 등 8개 중 하나)를 표현하지만, 3개의 큐비트는 한 번에 모든 상태를 동시에 표현할 수 있습니다. 이를 통해 양자 컴퓨터는 병렬로 여러 계산을 동시에 수행할 수 있습니다. 큐비트가 늘어날수록 연산 능력이 지수적으로 증가합니다.
양자 컴퓨터는 확률적으로 정답을 찾아갑니다. 확률이 높다고 무조건 정답은 아니지만 이를 보완하기 위해 매우 많은 시도를 동시에 진행한다. (검산과정) → 간섭이 많을 수록 확률이 높다 (정답 가능성이 매우 높음)
📝Qubit(큐비트)
정보를 저장하고 처리하는 양자적 단위
📝양자 푸리에 변환(QFT)
양자 푸리에 변환의 경우 일상생활 문제를 해결하기 위한 양자역학의 시도입니다. 입력 데이터(시간 또는 공간에 따른 함수)를 주파수 기반의 성분으로 분해하는 과정을 의미합니다.
주기성 탐지, 최적화 문제 해결에 탁월하다 주 사용 분야는 양자 컴퓨팅이며 상태를 주파수 영역으로 변환시켜 사용한다. 주기가 있는 즉, 주기가 있다는 건 특징이 있다는 것이고 특징이 있는 곳에 활용하기 좋다는 말입니다.
📝쇼어 알고리즘
1994년 피터 쇼어(Peter Shor)가 제안한 양자 알고리즘으로, 큰 정수를 빠르게 소인수분해하는 방법입니다.
양자컴퓨터에서 중요한데 고전 컴퓨터에서는 소인수분해는 매우 시간이 많이 걸리는 작업인데 특히 큰 수는 소인수 분해가 사실상 불가능합니다. 하지만 해당 알고리즘은 이 문제를 효율적으로 해결할 수 있습니다.
RSA는 소인수 분해의 "어려움"을 기반으로 한 암호화 체계로 보안에 문제를 일으킬 수도 있다는 말이 있습니다.
📝그로버 알고리즘
양자 컴퓨팅에서 사용되는 검색 알고리즘으로, 미지의 데이터베이스에서 원하는 항목을 빠르게 찾는 문제를 해결합니다. 이는 고전적인 검색 알고리즘보다 제곱근 속도로 빠릅니다
데이터를 학습하여 특정 작업을 수행할 수 있도록 컴퓨터를 훈련시키는 기술입니다. 인간은 데이터를 넣어주고 학습방법에 따라 훈련시킵니다. 예를 들면 고양이 사진을 주고 고양이 특징을 알려줬을 때 다른 고양이 사진을 주면 고양이라고 판단합니다.
훈련기술은 아래와 같습니다.
지도학습
입력 데이터와 정답이 주어진 상태에서 학습 → 이메일 스팸 필터
비지도학습
정답이 없는 데이터를 분석하고 패턴을 학습 → 이미지 분류
강화학습
보상을 기반으로 최적의 행동을 학습 → 알파고(바둑)
📝딥러닝
머신러닝의 하위 분야로 인공 신경망을 기반으로 데이터를 학습시키는 기술입니다. 머신러닝과 달리 사람의 개입 없이 중요한 특징을 알아서 추출합니다. 예를 들면 고양이 사진을 여러개를 주면 알아서 특징을 파악하고 다른 고양이 사진을 줬을 때 얘가 고양인지 파악할 수 있습니다.
입력층
입력데이터를 신경망에 전달하는 첫번째 층이다. 데이터만 전달하며 함수나 가중치 계산은 없다.
은닉층
입력 데이터를 변환하고 학습하는 신경망의 중간층이다. 은닉층이 많아질수록 더 복잡한 패턴 학습이 가능하다. 일반적으로 그렇지만 많은 시도를 해서 자기가 원하는 최적의 결과를 얻을때까지 해야한다. (사실 나도 안 해봐서 잘 모름)
출력층
신경망의 최종 결과를 출력하는 층이다.
📝머신러닝 vs 딥러닝
특징
머신러닝
딥러닝
데이터 처리
사람이 데이터를 분석하고 특징을 수동 정의
신경망이 데이터를 입력받아 특징을 자동으로 추출
데이터 요구량
비교적 적은 데이터로도 학습 가능
방대한 데이터 필요 (방대할 수록 성능이 올라간다)
컴퓨팅 자원
적은 연산 자원으로도 학습 가능
고성능 GPU 필요
비정형 데이터 처리
주로 구조화된 데이터(엑셀, 테이블) 처리에 적합
이미지, 텍스트, 음성 등 비정형 데이터를 처리 가능
특징 추출
사람이 직접 특징을 추출하게끔 설계
자동으로 특징 추출
📝LLM (대규모 언어 모델)
대규모 데이터로 학습된 언어 모델로, 자연어를 이해하고 생성하는 데 사용됩니다. LLM은 특히 수십억에서 수조 개의 매개변수(parameters)를 가진 신경망 모델로, 복잡한 언어적 패턴을 학습할 수 있습니다.
📝생성형 AI
데이터를 학습하여 새로운 콘텐츠(텍스트, 이미지, 음악 등)를 생성할 수 있는 AI 기술입니다. LLM과 딥러닝 기술을 이용해 텍스트, 이미지, 음성 등을 생성합니다.
장바구니의 전체 금액 >= 할인 기준금액일 경우 할인 프로모션을 적용시키는 시스템을 만드려고 합니다.
절차지향의 경우는 아래와 같습니다
// 할인
public class Promotion {
private Long cartId;
private Long basePrice;
public Money getBasePrice() {
return basePrice;
}
public void setCart(Long cartId) {
this.cartId = cartId;
}
}
// 장바구니
public class Cart {
private List<CartLineItem> items = new ArrayList<>();
public Long getTotalPrice() {
return items.stream().mapToLong(CartLineItem::getPrice).sum();
}
public int getTotalQuantity() {
return items.stream().mapToInt(CartLineItem::getQuantity).sum();
}
}
// 할인 프로세스
public class PromotionProcess {
public void apply(Promotion promotion, Cart cart) {
if (isApplicableTo(promotion, cart)) {
promotion.setCart(cart);
}
}
private boolean isApplicableTo(Promotion promotion, Cart cart) {
return cart.getTotalPrice() >= promotion.getBasePrice();
}
}
절차지향의 경우 할인, 장바구니의 데이터영역과 할인 프로세스를 처리하는 프로세스영역으로 나누어져있습니다.
객체지향의 경우는 아래와 같습니다.
// 할인 + 할인프로세스
public class Promotion {
private Cart cart;
private Long basePrice;
public void apply(Cart cart) {
if (cart.getTotalPrice() >= basePrice) {
this.cart = cart;
}
}
}
// 장바구니
public class Cart {
private List<CartLineItem> items = new ArrayList<>();
public Long getTotalPrice() {
return items.stream().mapToLong(CartLineItem::getPrice).sum();
}
public int getTotalQuantity() {
return items.stream().mapToInt(CartLineItem::getQuantity).sum();
}
}
절차지향과 다르게 객체지향은 데이터와 프로세스 영역으로 나누어져있지 않습니다. 할인과 관련된 것들끼리 다 모여있고 장바구니 관련된 것끼리 다 모여있습니다.
절차지향과 객체지향의 차이를 이야기할 때는 변경이라는게 중요합니다. 어떤 변경에 어떤 방식이 유연한지에 대한 것입니다. 위에 예제 기반으로 더 진행하자면 이번에는 최소금액 <= 장바구니금액 <= 최대금액일 경우에 할인이 적용되게끔 변경해달라는 요청이 있을 때 처리하는 방법입니다.
절차지향의 경우 아래와 같습니다.
// 할인 적용 프로세스
public class PromotionProcess {
public void apply(Promotion promotion, Cart cart) {
if (isApplicableTo(promotion, cart)) {
promotion.setCart(cart);
}
}
private boolean isApplicableTo(Promotion promotion, Cart cart) {
return cart.getTotalPrice() >= promotion.getMinPrice()
&& cart.getTotalPrice() <= promotion.getMaxPrice()
}
}
// 할인
public class Promotion {
private Long cartId;
private Long minPrice;
private Long maxPrice;
public Long getMinPrice() {
return minPrice;
}
public Long getMaxPrice() {
return maxPrice;
}
public void setCart(Long cartId) {
this.cartId = cartId;
}
}
절차지향의 경우 할인 적용시킬 기준 금액인 최소금액과 최대금액을 추가시켰습니다. Promotion과 PromotionProcess 두군데에서 수정이 이루어졌습니다.
객체지향의 경우 아래와 같습니다.
public class Promotion {
private Cart cart;
private Long minPrice;
private Long maxPrice;
public void apply(Cart cart) {
if (cart.getTotalPrice() >= basePrice &&
cart.getTotalPrice() >= maxPrice) {
this.cart = cart;
}
}
}
객체지향의 경우 Promotion에 Promotion관련 필드와 로직이 다 들어있기 때문에 Promoiton 한군데에서만 수정이 이루어졌습니다.
변경사항이 또 들어왔습니다. 이번에는 할인 조건을 하나 더 추가하는데 장바구니의 상품수 >= 프로모션 상품수일 경우 할인을 해줍니다. 할인을 받기 위해서는 설정한 프로모션 상품수보다 장바구니에 더 많이 담으면 할인을 해준다는 것이죠
절차지향의 경우 아래와 같습니다.
// 할인 프로세스
public class PromotionProcess {
public void apply(Promotion promotion, Cart cart) {
if (isApplicableTo(promotion, cart)) {
promotion.setCart(cart);
}
}
private boolean isApplicableTo(Promotion promotion, Cart cart) {
switch (promotion.getConditionType()) {
case PRICE:
return cart.getTotalPrice() >= promotion.getBasePrice();
case QUANTITY:
return cart.getTotalQuantity() >= promotion.getBaseQuantity
}
return false;
}
}
// 할인
public class Promotion {
public enum ConditionType {
PRICE, QUANTITY
}
private Long cartId;
private Long basePrice;
private int baseQuantity;
public ConditionType getConditionType() {
return conditionType;
}
public Money getBasePrice() {
return basePrice;
}
public int getBaseQuantity() {
return baseQuantity;
}
public void setCart(Long cartId) {
this.cartId = cartId;
}
}
절차지향의 경우는 가격 또는 개수에 따른 할인 조건이 두개라서 CondtionType을 할인 모델에 추가시켰습니다. 그리고 할인을 위한 기준 금액과 기준 개수가 필요하기 때문에 basePrice와 baseQuantity를 만들어줬습니다.
이럴경우 되게 코드가 지저분해보이며 모델도 추가해줘야하고 프로세스도 수정해야하는 여러군데에서 수정이 필요합니다. 또 할인 유형이 생기는 경우 더 늘어나게 됩니다.
객체지향의 경우 아래와 같습니다.
// 할인
public class Promotion {
private Cart cart;
private DiscountCondition condition;
public void apply(Cart cart) {
if (condition.isApplicableTo(cart)){
this.cart = cart;
}
}
}
// 장바구니
public class Cart {
private List<CartLineItem> items = new ArrayList<>();
public Long getTotalPrice() {
return items.stream().mapToLong(CartLineItem::getPrice).sum();
}
public int getTotalQuantity() {
return items.stream().mapToInt(CartLineItem::getQuantity).sum();
}
}
// 할인 인터페이스
public interface DiscountCondition {
boolean isApplicableTo(Cart cart);
}
// 가격 할인 구현체
public class PriceCondition implements DiscountCondition {
private Long basePrice;
@Override
public boolean isApplicableTo(Cart cart) {
return cart.getTotalPrice() >= basePrice;
}
}
// 개수 할인 구현체
public class QuantityCondition implements DiscountCondition {
private int baseQuantity;
@Override
public boolean isApplicableTo(Cart cart) {
return cart.getTotalQuantity() >= baseQuantity;
}
}
객체지향의 경우 다형성을 이용해야합니다. 그렇기 때문에 interface를 만들어줍니다. Promotion의 apply에서는 interface를 받게끔 해줍니다.
파일은 많아집니다만 이런식으로 객체지향식으로 설계가 되어있는 상태에서 다른 할인 유형에 대한 처리가 필요한 경우 DiscountCondition을 상속받아 구현하면 됩니다.
Promotion에서 apply는 수정할 필요도 없습니다. DiscountCondition을 상속받은 구현체만 껴주기만 하면 됩니다. 그리고 Promotion을 건들 필요가 없기 때문에 실질적으로 DiscountCondition을 상속받아서 만들어주기만 하면 됩니다. 파일 수정도 한군데에서만 일어나게 됩니다. 이곳저곳 수정할 필요도 없고 DiscountCondition을 무조건 받아야하기 때문에 절차적인 것처럼 임의대로 막 만들수도 없어 개발이 체계적으로 보입니다.
위와 같은 상황인 같은 기능을 다른로직으로 갈아껴야하는 상황에는 객체지향이 유리합니다만 무조건적으로 객체지향이 유리하지는 않습니다. 새로운 요구사항을 추가해봅시다. 장바구니에 대한 할인이였는데 이번에는 장바구니에 있는 하나의 상품에 대한 할인 적용을 만들어봅시다. 이번에는 상품인 Item에 대한 모델은 따로 안 만들고 할인에 대한 프로세스에만 집중해봅시다.
절차지향의 경우 아래와 같습니다.
// 할인 프로세스
public class PromotionProcess {
public void apply(Promotion promotion, Cart cart) {
if (isApplicableTo(promotion, cart)) {
promotion.setCart(cart);
}
}
private boolean isApplicableTo(Promotion promotion, Cart cart) {
switch (promotion.getConditionType()) {
case PRICE:
return cart.getTotalPrice() >= promotion.getBasePrice();
case QUANTITY:
return cart.getTotalQuantity() >= promotion.getBaseQuantity();
}
return false;
}
// 새로 추가된 상품에 대한 할인 적용
public boolean isApplicableTo(Promotion promotion, CartLineItem item) {
switch (promotion.getConditionType()) {
case PRICE:
return item.getTotalPrice() >= promotion.getBasePrice();
case QUANTITY:
return item.getTotalQuantity() >= promotion.getBaseQuantity();
}
return false;
}
}
절차지향의 경우 상품을 매개변수로 받아야 하기 때문에 또 다른 함수를 만듭니다. 다른 파일 건들 필요 없이 간단하게 PromotionProcess에만 추가하면 됩니다.
객체지향의 경우 아래와 같습니다.
// 할인
public class Promotion {
private Cart cart;
private DiscountCondition condition;
public void apply(Cart cart) {
if (condition.isApplicableTo(cart)) {
this.cart = cart;
}
}
}
// 할인 인터페이스
public interface DiscountCondition {
boolean isApplicableTo(Cart cart);
boolean isApplicableTo(CartLineItem item);
}
// Price 할인 구현체
public class PriceCondition implements DiscountCondition {
private Long basePrice;
@Override
public boolean isApplicableTo(Cart cart) {
return cart.getTotalPrice() >= basePrice;
}
@Override
public boolean isApplicableTo(CartLineItem item) {
return item.getPrice() >= basePrice;
}
}
// Quantity 할인 구현체
public class QuantityCondition implements DiscountCondition {
private int baseQuantity;
@Override
public boolean isApplicableTo(Cart cart) {
return cart.getTotalQuantity() >= baseQuantity;
}
@Override
public boolean isApplicableTo(CartLineItem item) {
return item.getQuantity() >= basePrice;
}
}
객체지향의 경우 Interface의 함수를 추가해야하고 이걸 무조건 구현해야하기 때문에 이걸 상속받은 구현체들의 코드는 다 추가되어야합니다. 또한 여기선 Promotion에 코드를 추가 안 했지만 Promotion 코드도 추가해야하기 때문에 총 4개의 파일을 수정해야합니다.
위와 같이 로직이 아예 다른 것을 추가할 때 객체지향의 경우 더 불리합니다. (장바구니할인 → 상품할인) 또 다른 예로는 타입 계층 전체 수정이 있는 경우입니다. Cart와 Promotion 모델을 합쳐서 CartWithPromotion 모델을 만들어야하는 예를 들어봅시다.
절차지향의 경우 아래와 같습니다.
public class PromotionProcess {
public CartWithPromotion convertToCartWithPromotion(
Promotion promotion,
Cart cart) {
CartWithPromotion result = new CartWithPromotion();
result.setTotalPrice(cart.getTotalPrice());
result.setTotalQuantity(cart.getTotalQuantity());
result.setPromotionBasePrice(promotion.getBasePrice());
result.setPromotionBaseQuantity(promotion.getBaseQuantity());
return result;
}
}
절차지향의 경우는 되게 간단하게 처리가 가능합니다. 두개의 모델을 받아서 그냥 새로운 모델에 넣어서 반환하면 됩니다.
객체지향의 경우 아래와 같습니다.
public class Promotion {
private Cart cart;
private DiscountCondition condition;
...
public CartWithPromotion convertToCartWithPromotion() {
CartWithPromotion result = new CartWithPromotion();
result.setTotalPrice(cart.getTotalPrice());
result.setTotalQuantity(cart.getTotalQuantity());
if (condition instanceof PriceCondition) {
result.setPromotionBasePrice(
((PriceCondition)condition).getBasePrice());
}
if (condition instanceof QuantityCondition) {
result.setPromotionBaseQuantity(
((QuantityCondition)condition).getBaseQuantity());
}
return result;
}
}
객체지향의 경우는 되게 복잡하게 처리해야합니다. Interface로 다형성을 유지해야하기 때문에 어떤 구현체가 들어올지 몰라 instanceof를 통해 클래스를 확인한 이후에 각각 다르게 처리해야합니다. 복잡하고 되게 어색합니다.
최종적으로 정리해 간단 요약하면 아래 표와 같습니다.
절차적인 설계
객체지향 설계
포맷 변경을 위한 데이터 변환 (데이터 합치기)
규칙에 기반한 상태 변경 (체계적) [복잡한 설계에 유리]
데이터 중심
행동 중심
데이터 노출
데이터 캡슐화
기능 추가에 유리 (아예 새로운 기능 → 장바구니가 아닌 상품 할인 기능이 필요한 경우)
타입 확장에 유리 (본질적인 기능은 같지만 다양하게 확장 가능 → 인터페이스로 인한 할인 확장)
데이터와 프로세스가 명확히 분리
데이터 프로세스 같이 존재 (클래스 안에 할인 관련된 데이터와 할인 프로세스가 같이 들어있다)
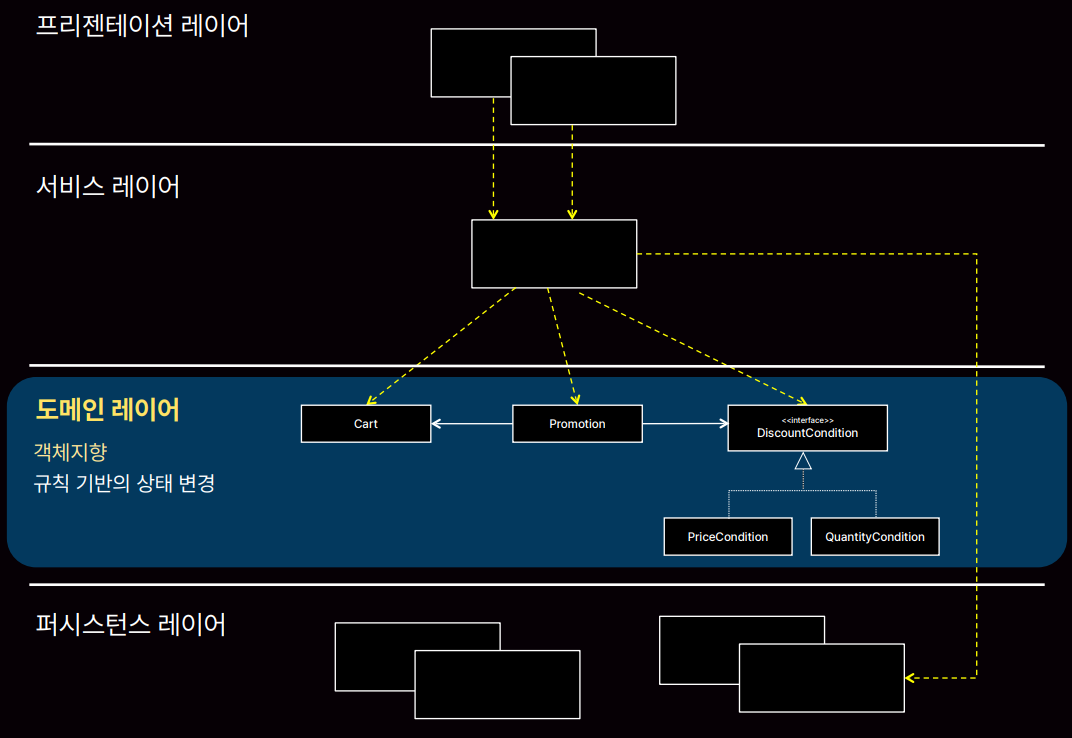
도메인 레이어의 경우 객체지향이 좋습니다. (어떤 할인 내용을 적용시킬지 = 할인이라는 공통 분모)
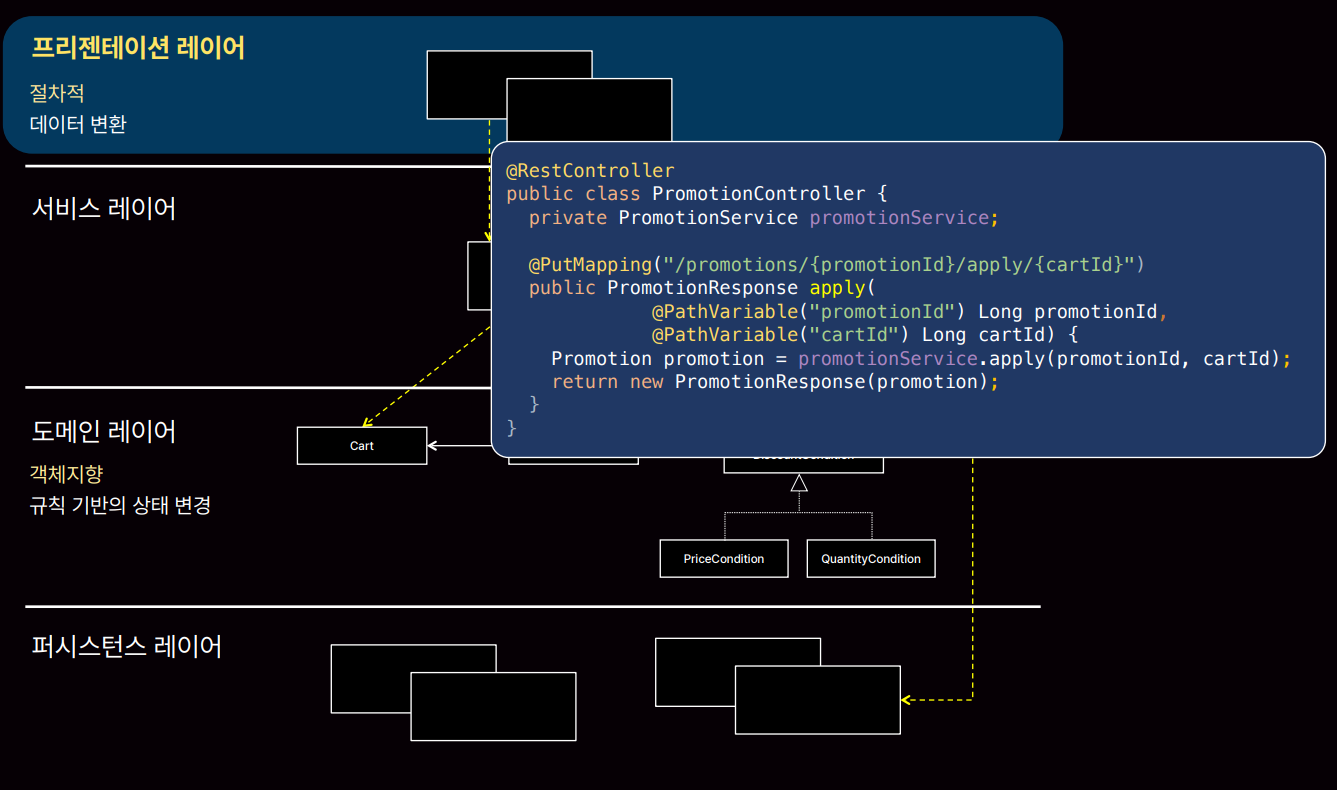
프레젠테이션 레이어의 경우 데이터를 반환하기 때문에 절차지향에 좋습니다.
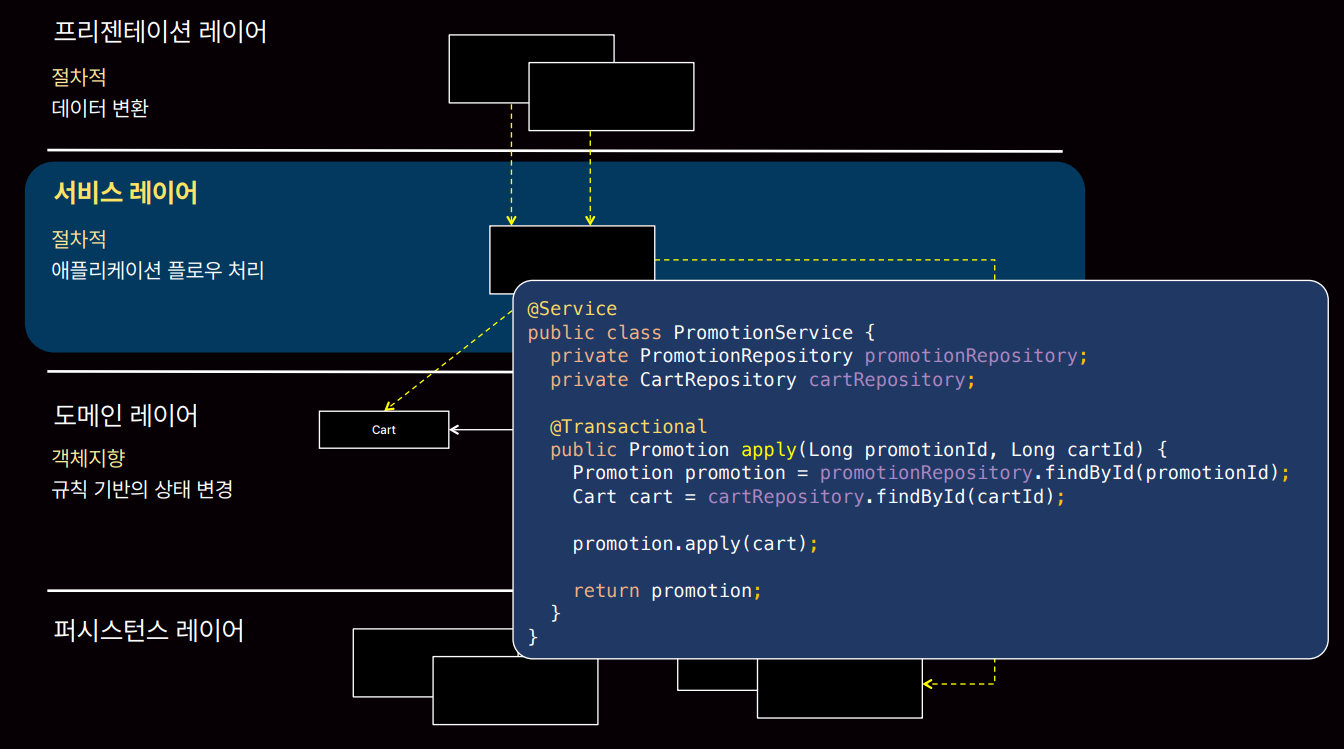
서비스 레이어의 경우 비즈니스로직은 순차적 처리가 필요하기 때문에 절차지향에 좋습니다. (서비스에 어떤 할인을 적용시킬지 이런 내용인 인터페이스를 상속받은 구현체가 들어가서 절차지향에 객체지향이 들어간 형태입니다.)
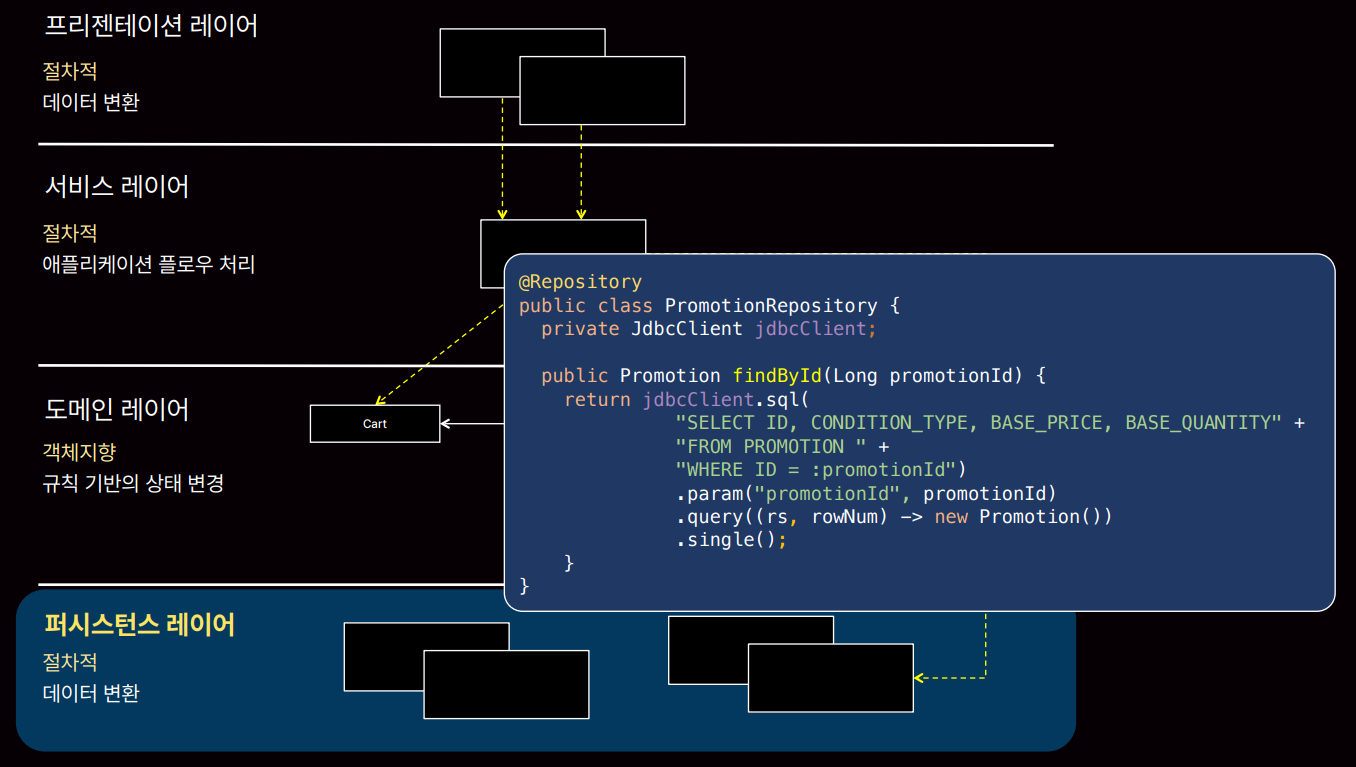
퍼시스턴스 레이어의 경우 DB 쿼리문 조회하고 이런 부분은 순차 처리가 필요하기 때문에 절차지향에 좋습니다.
이미 우리는 상황에 맞게 절차지향과 객체지향을 섞어 쓰고 있습니다. 즉, 우월하다 이런 건 없고 상황에 맞게 잘 써야합니다.
📝 인터페이스 vs 추상클래스
인터페이스
public interface Animal {
void eat(); // 메서드 선언 (구현 X)
void sleep();
}
public class Dog implements Animal {
@Override
public void eat() {
System.out.println("Dog eats.");
}
@Override
public void sleep() {
System.out.println("Dog sleeps.");
}
}
인터페이스의 특징은 아래와 같습니다.
다중 상속 가능
행동의 규약 정의 → 해당 메소드는 반드시 구현해야 함
무엇을 해야하는 가를 정의한다.
추상클래스
public abstract class Animal {
private String name; // 멤버 변수
public Animal(String name) {
this.name = name;
}
public void breathe() {
System.out.println(name + " is breathing."); // 일반 메서드
}
public abstract void eat(); // 추상 메서드
}
public class Dog extends Animal {
public Dog(String name) {
super(name);
}
@Override
public void eat() {
System.out.println("Dog eats.");
}
}
추상클래스의 특징은 아래와 같습니다.
단일 상속
추상클래스에서 이미 구현되어있기 때문에 상속받아서 직접 구현 안 해도 된다.
기본적인 공통기능에 사용하며 만약 커스텀이 필요한 경우 @overrid로 재정의해서 사용하면 좋다.
공통메서드를 사용하거나 커스텀이 필요한 경우 @override 재정의가 가능하기 때문에 interface처럼 규약에 덜 얽매인다.
서로 다른 도메인에 요청을 보낼때 요청에 Credentials 정보를 담아서 보낼지에 대한 여부입니다.
기본적으로 브라우저가 제공하는 요청 API 들은 별도의 옵션 없이 브라우저의 쿠키와 같은 인증과 관련된 데이터를 함부로 요청 데이터에 담지 않도록 되어있다. 이는 응답을 받을때도 마찬가지이다. 따라서 요청과 응답에 쿠키를 허용하고 싶을 경우, 이를 해결하기 위한 옵션이 바로 withCredentials 옵션을 넣어야한다
credential 정보가 포함된 요청은 아래와 같습니다.
쿠키를 첨부해서 보내는 요청
헤더에 Authorization 항목이 있는 요청
📝HttpOnly
자바스크립트로부터 쿠키 접근을 차단하여 XSS 공격 방지를 해준다
📝Secure
HTTPS를 통해서만 쿠키를 전송하여 MITM 공격 방지할 수 있다
📝SameSite
쿠키가 서로 다른 사이트에서 전송되지 않도록 제한 하는 속성으로 CSRF 공격을 방지하는데 사용됩니다.
Strict
쿠키가 같은 사이트 내에서만 전송됩니다. 외부 사이트에서 링크 클릭하여 들어오는 경우 쿠키가 전송되지 않습니다.
Lax
쿠키가 같은 사이트 내에서만 전송됩니다. 외부 사이트에서 gET 요청이 발생한 경우에는 쿠키가 전송 될 수 있습니다. → 예를 들면 다른 곳에서 쿠팡 링크로 들어왔을 때 어떤 검색어를 통해서 들어왔는지에 대한 쿠키에 대한 정보를 파악하기 위해 필요하다
None
쿠키가 모든 사이트 간 전송될 수 있습니다. 이 옵션을 사용할 때는 Secure 속성을 함께 사용해야합니다.