반응형
📝UTF-8
유니코드사에서 모든 언어를 표현하기 위해 만든 코드표
길이가 앞에 뭐가 붙냐에 가변적으로 1바이트로 읽을지 2바이트 읽을지 .. 정한다
[영문 1바이트 한글 3바이트] 문자 한개를 표현하기 위해 8bit 필요하고 문자 하나를 표현하기 위한 바이트 범위 1~ 4바이트 모바일에도 잘 쓰이기 때문에 UTF-8을 자주 사용
📝UTF-16
문자 한개 16bit 필요하고 문자 하나를 표현하기 위한 바이트 범위 2~4 [영문 2바이트 한글 2바이트]
📝인코딩
사람이 인지할 수 있는 형태(글자나 숫자등..)의 데이터를 약속된 규칙에 의해 컴퓨터가 사용하는 0과 1로 변환하는 과정
📝디코딩
인코딩된 파일(0 1 로 만들어버린)을 읽어내는 과정
📝MS949
한글 확장 완성형
📝CP949
한글 완성형
📝MS949 vs CP949
MS949의 경우 CP949와 같다는 말이 많지만 MS949의 경우 똠방각하 표현이 가능하지만 하다
CP949의 경우 똠방각하 표현이 불가능 또한 MS949라는 건 자바에서만 사용한다
즉, CP949끼리는 CP949끼리 통신하고 MS949의 경우 MS949끼리 통신하는게 좋다
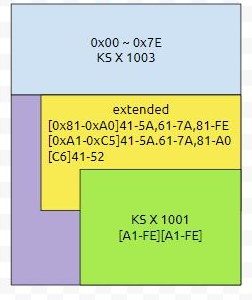
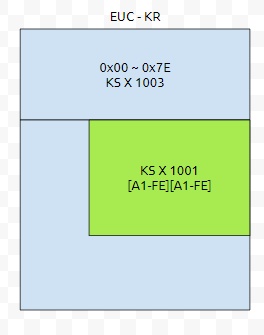
📝EUC-KR
EUC는 아시아계 문자를 표현하기 위해 개발한 코드 체계이다.
→ EUC-KR = KSC5636 + KSC5601
📝KS-5601
자주 쓰이는 2350자만 가나다 순으로 배열이 되어있다.
한글 문자수는 11176개라 나머지 8000여개는 없는 셈이다.
📝KSC5636
영문자에 대한 표준 기존 ASCII Code에서 역슬래쉬(\)를 원(\) 표시로 대체
📝ISO-8859-1
서유럽 언어 표기에 필요한 문자 코드
- 이미 깨져서 생성된 String 객체의 바이트 배열은 어떤 방식으로든 복구 불가능하다
- EUC-KR < CP949 범위가 더 넓다
반응형