📝Point To Point
보내는 사람이 큐를 통해서 메시지를 전달하면 받는 사람이 큐에서 하나씩 꺼내 읽는 방식으로 Point To Point는 서버끼리 연결한 1대1의 상태이다
📝메세징 시스템
메시지는 전송되는 정보의 블록이나 패킷을 의미한다 에를 들면 로그 데이터, 이벤트 메시지 등 API 로 호출할 때 보내는 데이터를 처리하는 시스템입니다
📝Kafka
기존 네트워크 방식은 Point To Point로 서버끼리 연결한 1대1의 상태인데 기능이 늘어나 서버가 늘어나고 각 서버끼리 연결이 많아질수록 복잡해지는 시스템을 가지고 있었다 이러한 네트워크에서는 문제점들이 아래와 같은 문제점들이 존재한다
- 통합 / 중앙화된 정송 영역이 없음 → 연결이 갈수록 복잡하다
- 문제가 발생했을 때 여러 시스템을 확인해야 한다 → 어디에서 장애가 일어났는지 문제 해결이 어려워진다
- 연결된 시스템 마다 제각기 다른 방법으로 구현 될 수 있다 → 복잡도 증가
이러한 문제점들을 해결하기 위해 카프카 개발팀에서는 다음과 같은 목표를 가지고 있었습니다
- 프로듀서와 컨슈머의 분리 → 역할 분리
- 시스템 확장이 쉽게 만들기
- End To End → 이벤트 / 데이터 흐름을 중앙에서 관리하는 방식
그래서 카프카는 pub/sub 모델을 기반으로 만들어진 메세징 시스템이 됩니다
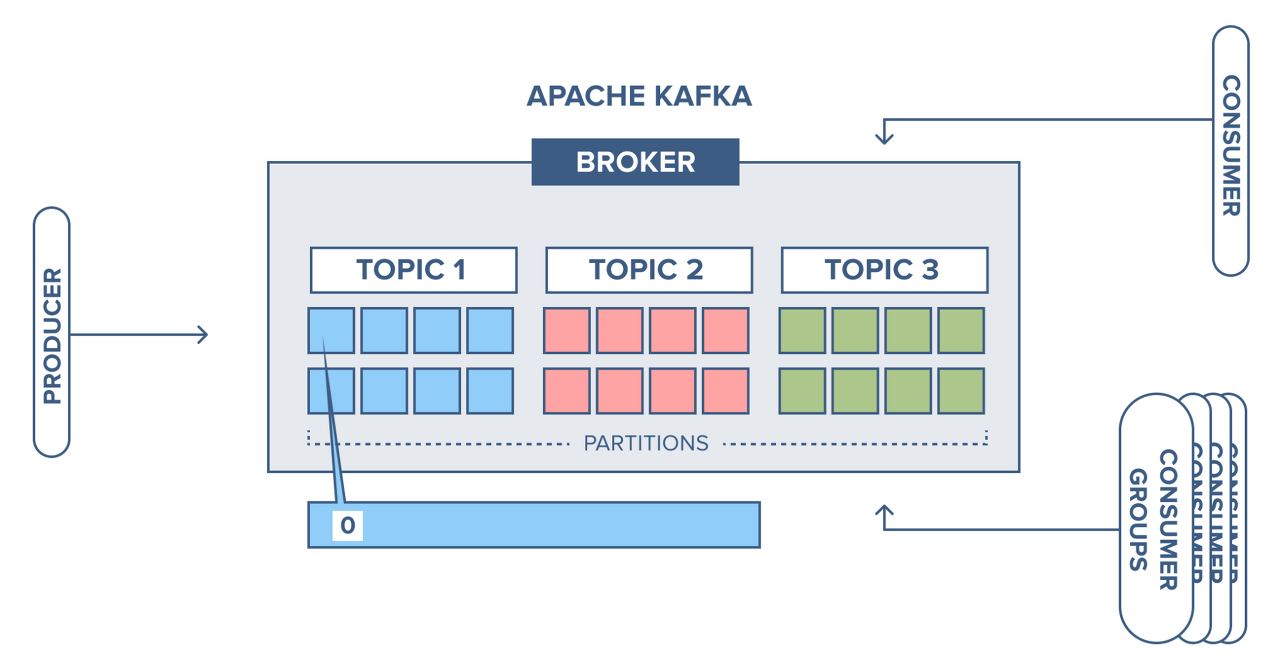
카프카를 설명하기 위한 용어들이 있습니다
- Producer
- 데이터를 생성하고 특정 토픽으로 전송하는 주체 → 메시지(요청 정보 + 데이터)를 카프카 시스템에 보내는 역할
- Kafka System (Kafka Cluter)
- 중앙 메시징 시스템으로 메시지를 읽어서 요청한 곳에 보내는 역할 → 주문 시스템에서 주문했을 때(Producer) 해당 처리 시스템(Consumer)으로 보내는 역할
- Consumer
- 특정 토픽에서 메시지를 소비하여 처리하는 역할 → 주문 시스템에서 주문 관련 정보를 DB에 넣은 후 다시 카프카로 전달
- PARTITIONS
- 파티션은 메세지를 저장하는 물리적인 파일 → 사용자가 요청한 정보들을 의미 (N명이 요청하면 N개)
- Topic
- 토픽은 메시지를 관리하는 주체로서, 비슷한 종류의 데이터를 그룹화하는 역할로 여러개의 파티션을 가질 수 있다 → 카테고리라고 생각하면 된다 "주문 시스템 처리 서비스"가 토픽이 될 수 있다
- Broker
- 여러개의 토픽을 가지며 Kafka 그 자체라고 생각하면 된다
- Zookeeper
- 브로커 간의 조율과 클러스터의 메타데이터 관리를 위해 Apache Zookeeper를 사용
- 동작 과정
- 사용자 요청(Partitions)들이 들어오면 Producer로 전달하고 Kafka로 보낸 뒤 Topic에 맞게끔 큐에 쌓인다 그 뒤 역할에 맞게 Consumer로 보내 처리되는 형태이다
💗장점
- 확장성 → 수평 확장이 가능하다
- 래플리카 → 래플리카로 노드 장애나 데이터 손실에 안정적 운영이 가능
- pub/sub 구조 → 확장에 더 용이하다
- 배울 수 있는 환경이 넓음 → 생태계가 구성 됨
- 빠른 처리 → 카프카는 대량의 메시지를 빠르게 처리할 수 있으며 파티셔닝을 통해 데이터 분산 저장 처리해 높은 처리량
💗왜 빠른가?
- DISK I/O 최적화 → 세그먼트단위로 저장하며 순차적인 디스크 I/O가능하게 한다 [디스크 읽을 떄 이리읽었다 저리읽었다 하지 않음]
- 클러스터 구성 → 분산처리로 처리 능력 향상
- 메시지 배치 처리 → 네트워크 및 디스크 I/O 비용 감소
- Zero-Copy
- 토픽 파티셔닝 → 토픽 파티션 병렬 처리 지원
⚠️단점
- 시스템이 복잡하다
- 러닝커브가 필요하다
- 카프카는 대량의 데이터를 처리하고 저장하기 위해 상당한 자원이 필요 → 오버헤드가 발생할 수도 있음 (DISK I/O) → 프로듀서 정보, 래플리카, 컨슈머에서 DISK Read 등 많은 DISK I/O 발생
📝pub/sub 모델
- 중앙에 메시징 시스템 서버(카프카)를 두고 메시지를 보내고(publish), 받는(subscript) 형태의 통신이다
- 구독을 신청한 수신자만 메시지를 전달받을 수 있다
- 개체가 빠지거나 수신 불능이 되어도 메시징 시스템만 살아있으면 전달한 메시지가 유실될 가능성이 없다
- N:M으로 연결되는 게 아니라 확정성에 용이
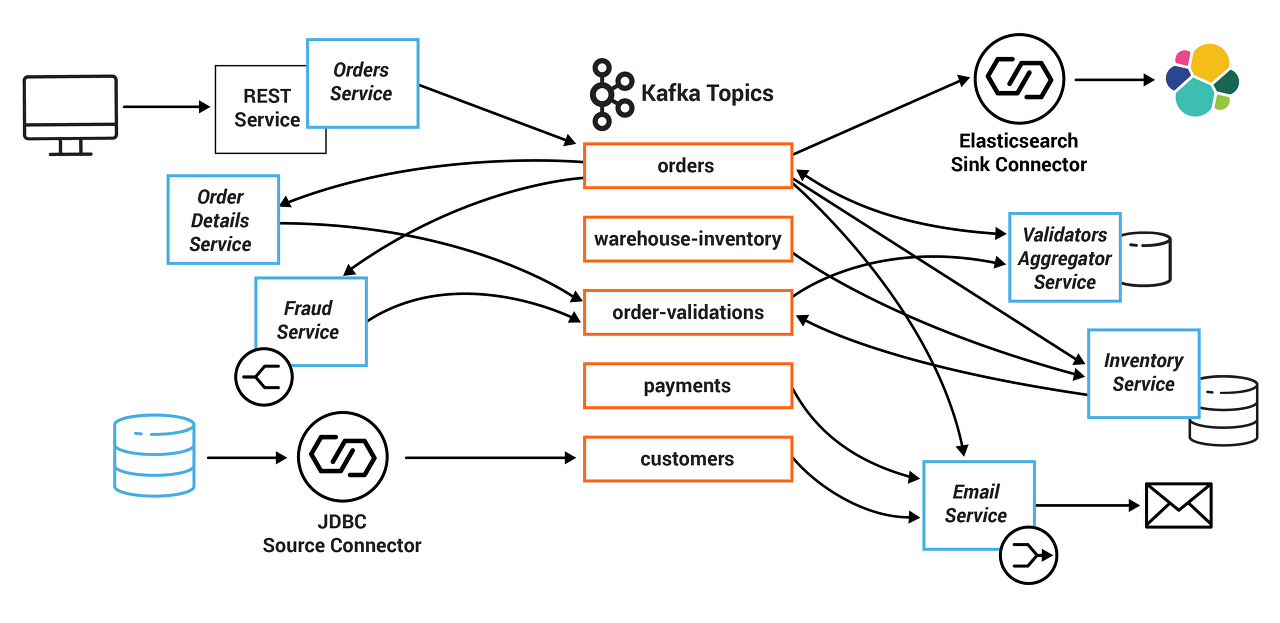
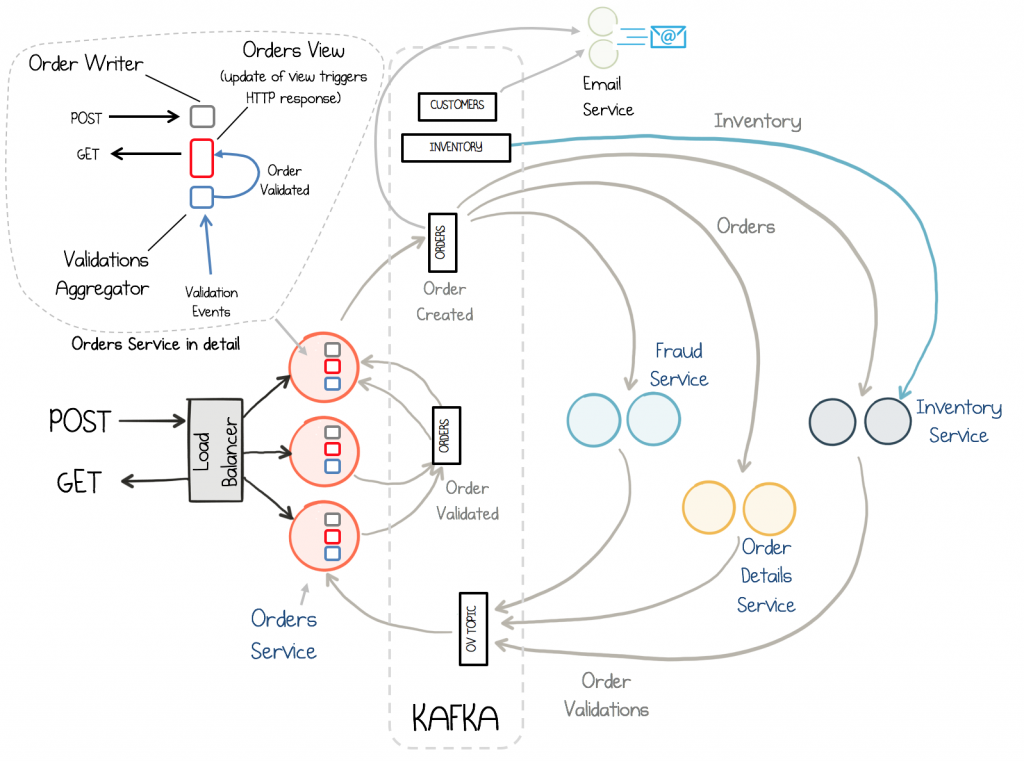
카프카 적용 예제
📝Haddop
하나의 성능 좋은 컴퓨터를 이용하여 데이터를 처리하는 대신 적당한 성능의 범용 컴퓨터 여러 대를 클러스터화하고 큰 크기의 데이터를 클러스터에서 병렬로 동시에 처리하여 분산처리 저장하는 대용량 처리에 특화된 솔루션입니다
📝Hive
데이터 웨어하우스 기능을 제공하는 데이터베이스 시스템으로 SQL과 유사한 Hive Query Language (HiveQL)을 사용하여 대용량 데이터 세트를 쿼리하고 분석할 수 있습니다 (Hadoop 사용시 분산 저장되어있기 때문에 그걸 통합시켜주는 시스템)
📝Hue
Hadoop 클러스터와 연동하여 사용자 친화적인 웹 인터페이스를 제공하는 오픈 소스 사용자 인터페이스 (UI) 플랫폼
🔗 참고 및 출처
https://log-laboratory.tistory.com/144
https://victorydntmd.tistory.com/343
https://goneoneill.tistory.com/48
https://choonsik-lab.tistory.com/entry/코드-스니핏-Code-Snippet-이란
https://kaki104.tistory.com/809